SRE-Zero v1.5: Public Draft and 25-Task Baseline Sweep
Making the SRE-Zero v1.5 technical report draft public, with paper PDF, plots, JSON records, and preliminary baseline results.
SRE-Zero v1.5: Public Draft and 25-Task Baseline Sweep
I am making the SRE-Zero v1.5 technical report draft publicly available, together with the expanded 25-task baseline sweep.
Draft v1.5 / Technical Report / Work in Progress
This is an early public draft. The current results are preliminary and are intended to validate the benchmark design, not to provide final model rankings.
SRE-Zero is an early-stage research benchmark for studying reliable tool-using LLM agents in simulated incident-response workflows. Agents must inspect simulated infrastructure state, gather relevant evidence, apply minimal remediations, and submit final incident resolutions under a step budget.
The v1.5 draft updates the first report with the expanded 25-task environment and a broader baseline sweep across deterministic, prompting-only, ReAct-style, open-source, and frontier-model agents.
Download the v1.5 bundle
The blog post, paper, plots, and records are stored together under blogs/4/.
Paper
Main evaluation JSON
What changed from v1
The main update is the expanded benchmark environment.
The suite now includes:
- 25 deterministic incident-response tasks
- 5 simulated services:
web_server,database,cache,message_queue, andload_balancer - easy, medium, and hard tasks
- distractor logs
- noisy metrics
- step budgets
- invalid action handling
- partial-credit rewards
- metrics for evidence coverage, wrong fixes, premature resolution, and distractor failures
The goal is still modest: build a benchmark that can expose useful differences between tool-using agent strategies before making stronger claims about model performance.
Run setup
The v1.5 sweep used:
- Task suite: 25 deterministic incident-response tasks
- Services:
web_server,database,cache,message_queue,load_balancer - Deterministic baselines: 5 episodes per task
- LLM baselines: 1 episode per task
- Seed:
0 - JSON records: listed in the full artifact downloads section
- Plots: shown below, with raw files listed in the full artifact downloads section
The run evaluated random, scripted, prompting-only, ReAct-style, open-source, and frontier baselines.
Because the LLM baselines use only one episode per task, these numbers should be treated as directional signals rather than statistically stable estimates.
Main result
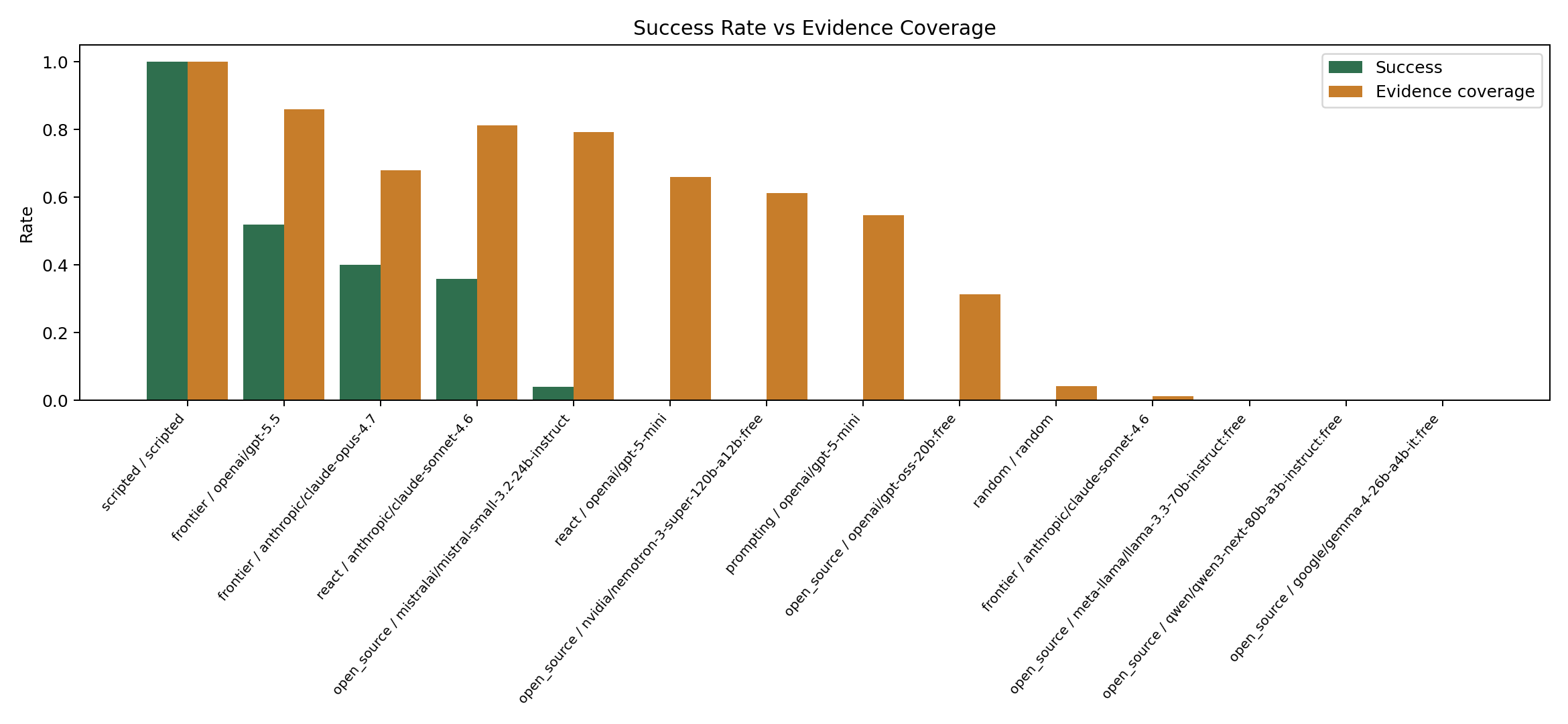
The strongest signal remains the same:
Evidence gathering and final resolution are separable.
In the 25-task sweep, several agents gathered relevant evidence without reliably resolving incidents. For example:
mistralai/mistral-small-3.2-24b-instructreached 0.79 evidence coverage but only 0.04 success.- ReAct
openai/gpt-5-minireached 0.66 evidence coverage but 0.00 success. - Prompting
openai/gpt-5-minireached 0.55 evidence coverage but 0.00 success.
This is the kind of behavior SRE-Zero is meant to measure. A final success score alone does not show whether an agent inspected useful state, chose invalid tools, followed distractors, applied the wrong fix, or stopped too early.
Preliminary results
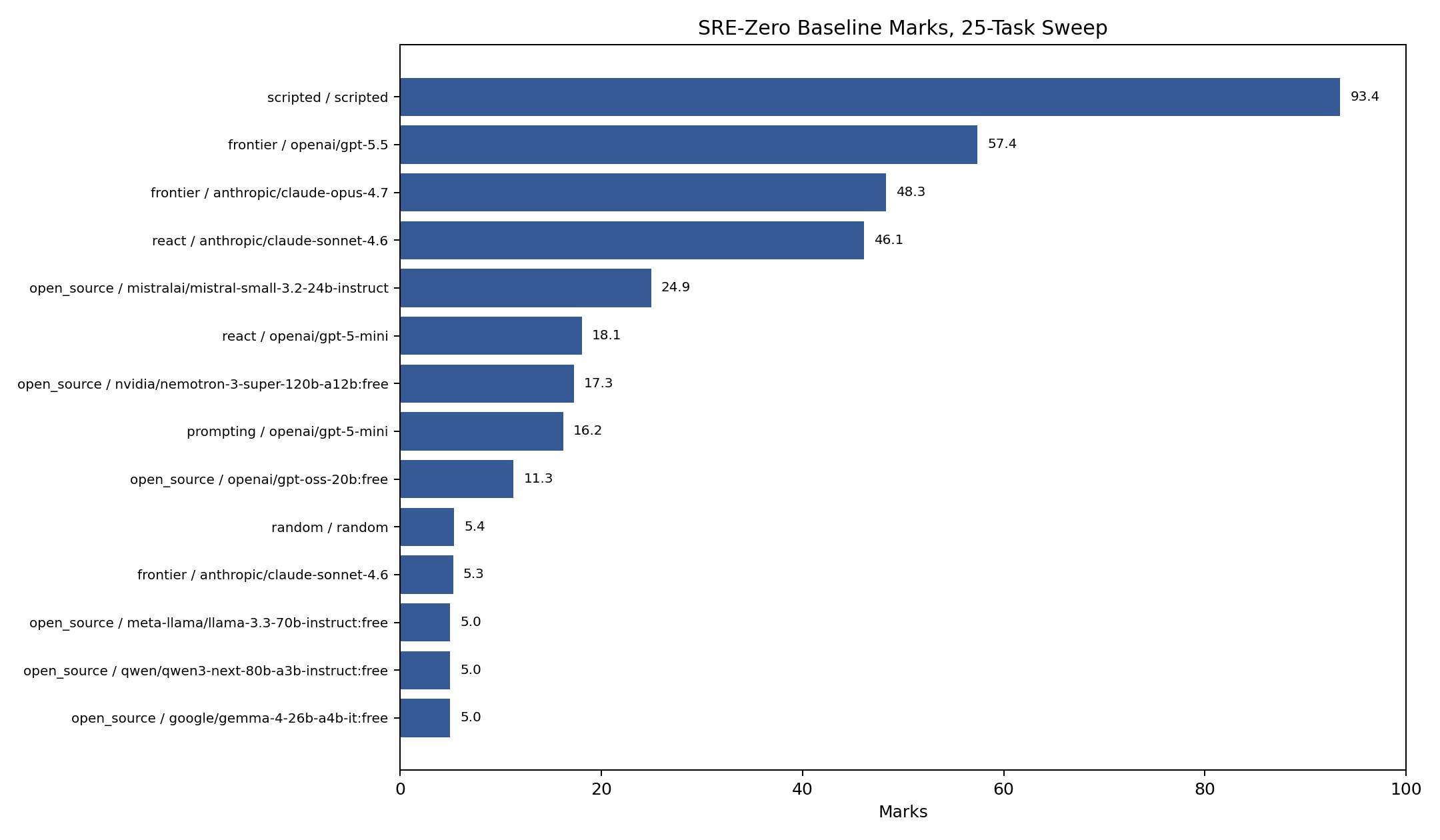
"Marks" is a composite score from 0-100 combining success, reward, evidence coverage, invalid-action rate, efficiency, and error penalties.
| Baseline | Model | Marks | Success | Reward | Evidence | Invalid | Errors |
|---|---|---|---|---|---|---|---|
| scripted | deterministic/scripted | 93.4 | 1.00 | 0.943 | 1.00 | 0.00 | 0 |
| frontier | openai/gpt-5.5 | 57.4 | 0.52 | 0.527 | 0.86 | 0.01 | 2 |
| frontier | anthropic/claude-opus-4.7 | 48.3 | 0.40 | 0.470 | 0.68 | 0.06 | 5 |
| react | anthropic/claude-sonnet-4.6 | 46.1 | 0.36 | 0.417 | 0.81 | 0.13 | 0 |
| open_source | mistralai/mistral-small-3.2-24b-instruct | 24.9 | 0.04 | 0.099 | 0.79 | 0.00 | 0 |
| react | openai/gpt-5-mini | 18.1 | 0.00 | 0.012 | 0.66 | 0.08 | 24 |
| open_source | nvidia/nemotron-3-super-120b-a12b:free | 17.3 | 0.00 | 0.039 | 0.61 | 0.19 | 5 |
| prompting | openai/gpt-5-mini | 16.2 | 0.00 | 0.014 | 0.55 | 0.01 | 20 |
| open_source | openai/gpt-oss-20b:free | 11.3 | 0.00 | 0.003 | 0.31 | 0.01 | 20 |
| random | deterministic/random | 5.4 | 0.00 | 0.004 | 0.04 | 0.11 | 0 |
These numbers are not a leaderboard. Several provider-backed runs had errors, and the run is too small for final model comparisons. The useful point is that the environment creates a meaningful random floor, scripted upper bound, and intermediate failure modes that can be inspected.
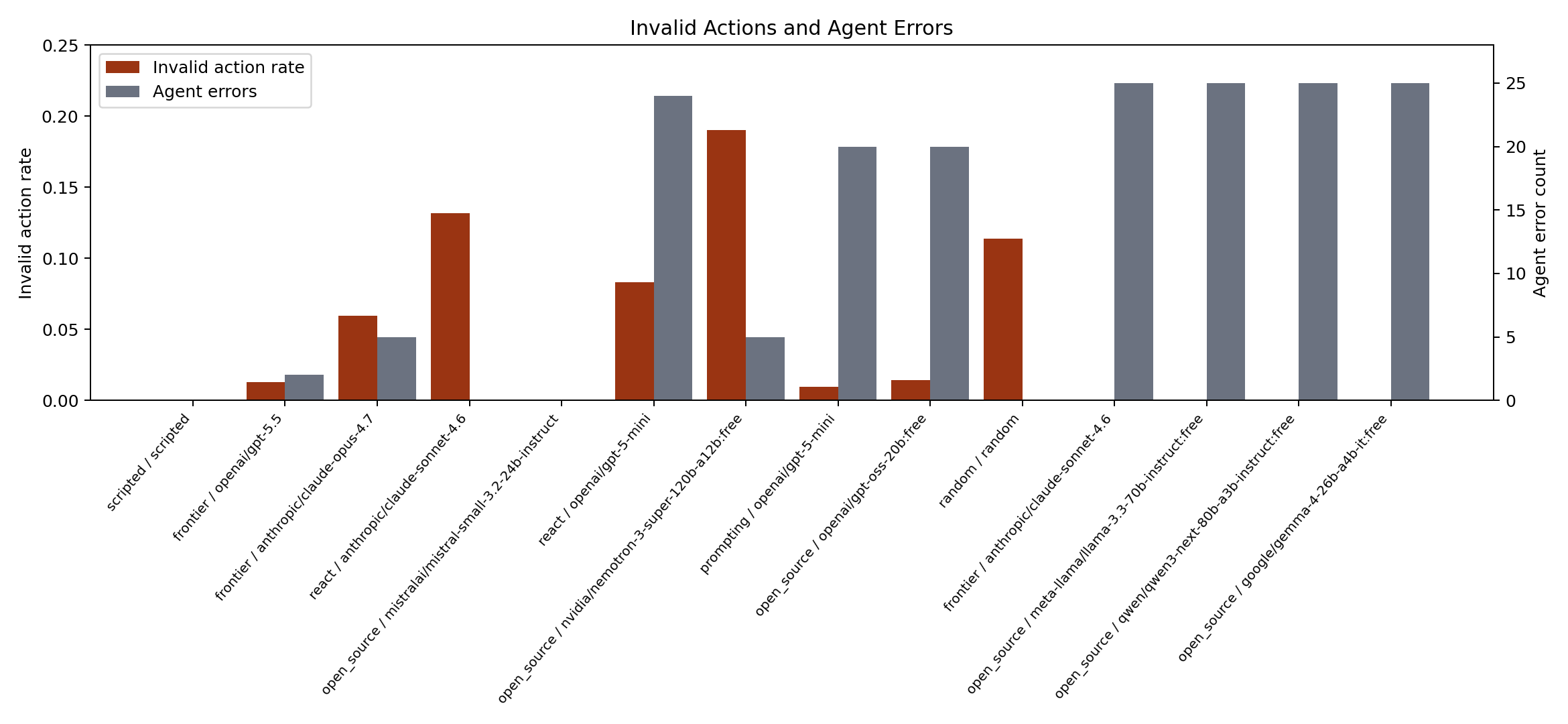
Error handling
SRE-Zero records invalid actions and agent errors separately from task success. This matters because some failures are model-policy failures, while others are provider or output-format failures.
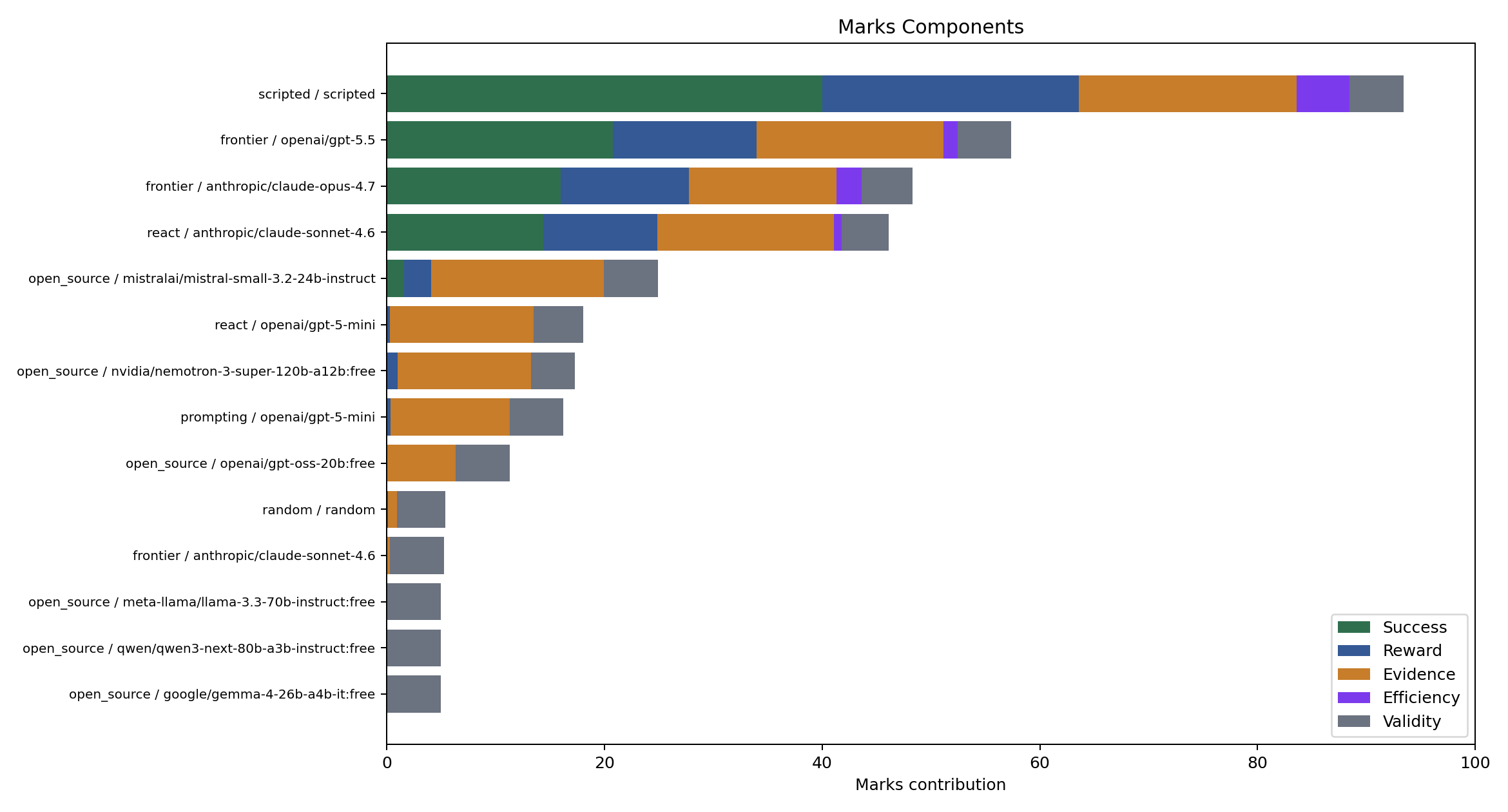
Marks components
The marks score combines success, reward, evidence, efficiency, action validity, and error handling.
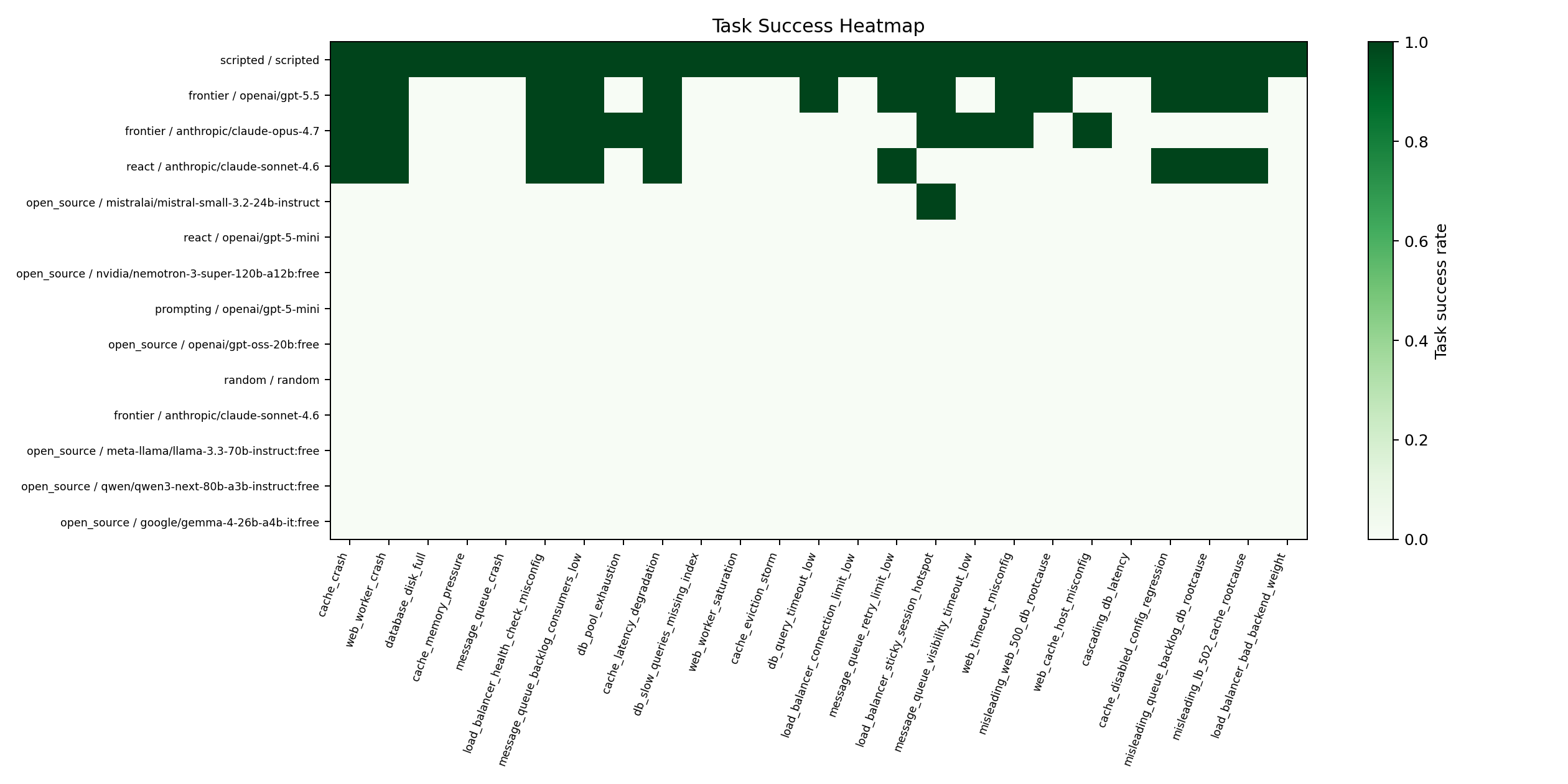
Task-level view
Different agents fail on different subsets of tasks.
Why publish the draft now
The project is still early, but the benchmark is now large enough to make the research direction concrete. The v1.5 report gives a snapshot of the environment design, task suite, metrics, baseline agents, and current limitations.
Publishing this draft now makes the assumptions and failure modes visible while the benchmark is still being shaped.
Limitations
The v1.5 report is intentionally cautious.
Important limitations:
- one seed
- one episode per LLM task
- a limited model/provider set
- provider errors in several API-backed runs
- simulated services rather than real infrastructure
- no human SRE baseline
- no confidence intervals
The current claim is not that one model is definitively better than another. The claim is that SRE-Zero is beginning to expose useful, environment-grounded differences in tool use.
Next
The next work is to run more seeds, separate provider failures from model reasoning failures more carefully, expand the task suite, and add stronger reporting around confidence intervals and failure categories.
The broader goal remains the same: build a serious, simulation-only benchmark for studying reliable tool-using agents in incident-response workflows.
Full artifact downloads
JSON browser
Per-run JSON records
- Random baseline, 5 episodes
- Scripted baseline, 5 episodes
- Prompting, openai/gpt-5-mini
- ReAct, openai/gpt-5-mini
- ReAct, anthropic/claude-sonnet-4.6
- Frontier, openai/gpt-5.5
- Frontier, anthropic/claude-sonnet-4.6
- Frontier, anthropic/claude-opus-4.7
- Open-source, google/gemma-4-26b-a4b-it-free
- Open-source, meta-llama/llama-3.3-70b-instruct-free
- Open-source, mistralai/mistral-small-3.2-24b-instruct
- Open-source, nvidia/nemotron-3-super-120b-a12b-free
- Open-source, openai/gpt-oss-20b-free
- Open-source, qwen/qwen3-next-80b-a3b-instruct-free