SRE-Zero: Environment-Grounded Evaluation for Reliable Tool-Using Agents
Publishing the first public SRE-Zero technical report draft and preliminary benchmark results.
SRE-Zero: Environment-Grounded Evaluation for Reliable Tool-Using Agents
Draft v1 / Technical Report / Work in Progress
This is an early public draft. The current results are preliminary and are intended to validate the benchmark design, not to provide final model rankings.
I am publishing the first technical report draft for SRE-Zero, an early-stage research benchmark for studying reliable tool-using LLM agents in simulated incident-response workflows.
The project asks a narrow question: can an agent gather evidence, diagnose a simulated infrastructure incident, apply a minimal remediation, and submit the correct final resolution under a step budget?
The benchmark is intentionally simulation-only. It does not execute shell commands, touch real infrastructure, or perform any live remediation. Agents interact with structured tools such as inspect_logs(service), inspect_metrics(service), check_status(service), update_config(service, key, value), and resolve_incident(root_cause, fix).
What v1 contains
The v1 draft describes the initial SRE-Zero environment, task suite, reward design, metrics, and baseline agents. The current paper results use the earlier 15-task suite.
The v1 bundle includes:
- the technical report PDF
- evaluation JSON records
- generated plots
- baseline trajectories and summaries
The website copy of the bundle is stored under blogs/3/, and the files below are linked directly from the post.
Download the v1 bundle
Paper
Main evaluation JSON
The main signal
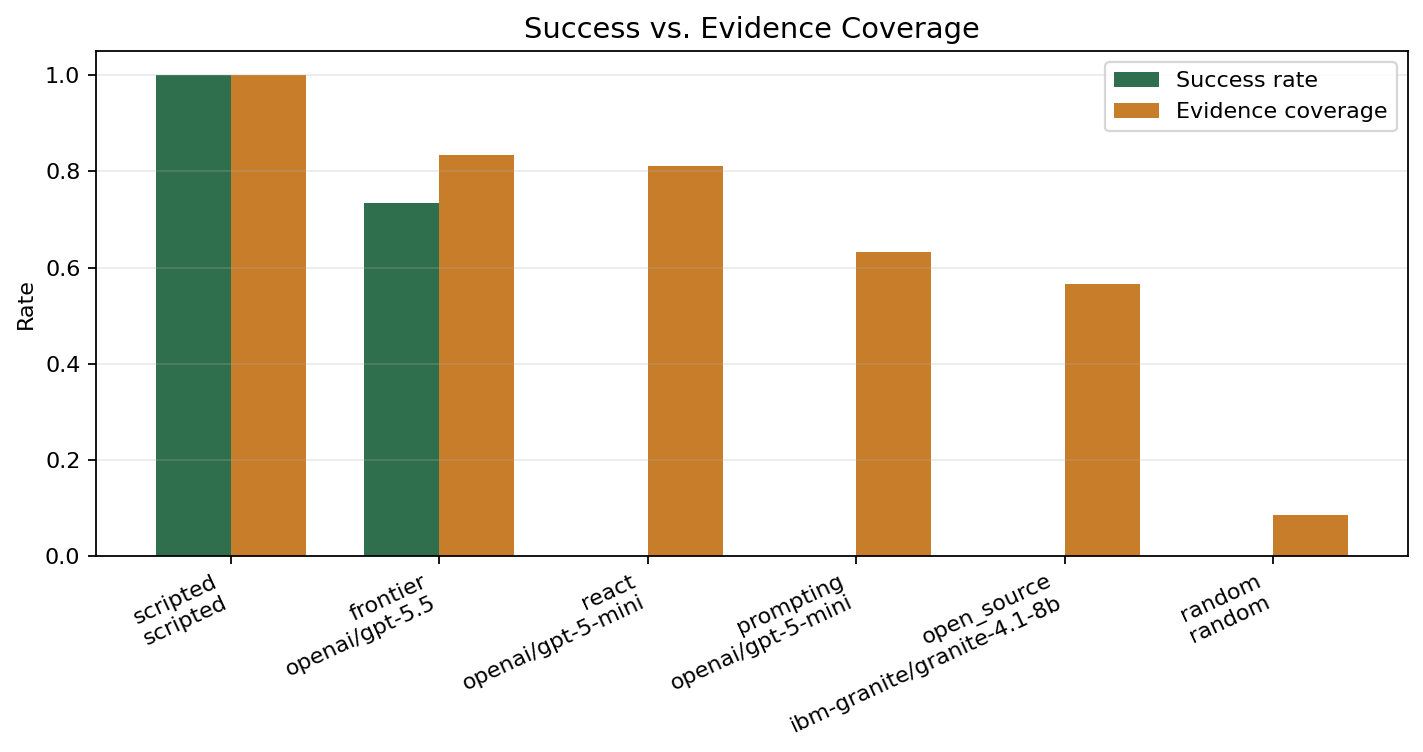
The most interesting early signal is that evidence gathering and final resolution are separable.
In the preliminary sweep, the ReAct-style openai/gpt-5-mini run reached 0.81 evidence coverage but 0.00 success. The prompting-only openai/gpt-5-mini run reached 0.63 evidence coverage with 0.00 success.
That means the agents were often able to inspect useful logs, metrics, or configuration, but still failed to turn that evidence into the correct minimal fix and final incident resolution. This is exactly the kind of distinction that a benchmark like SRE-Zero should make visible.
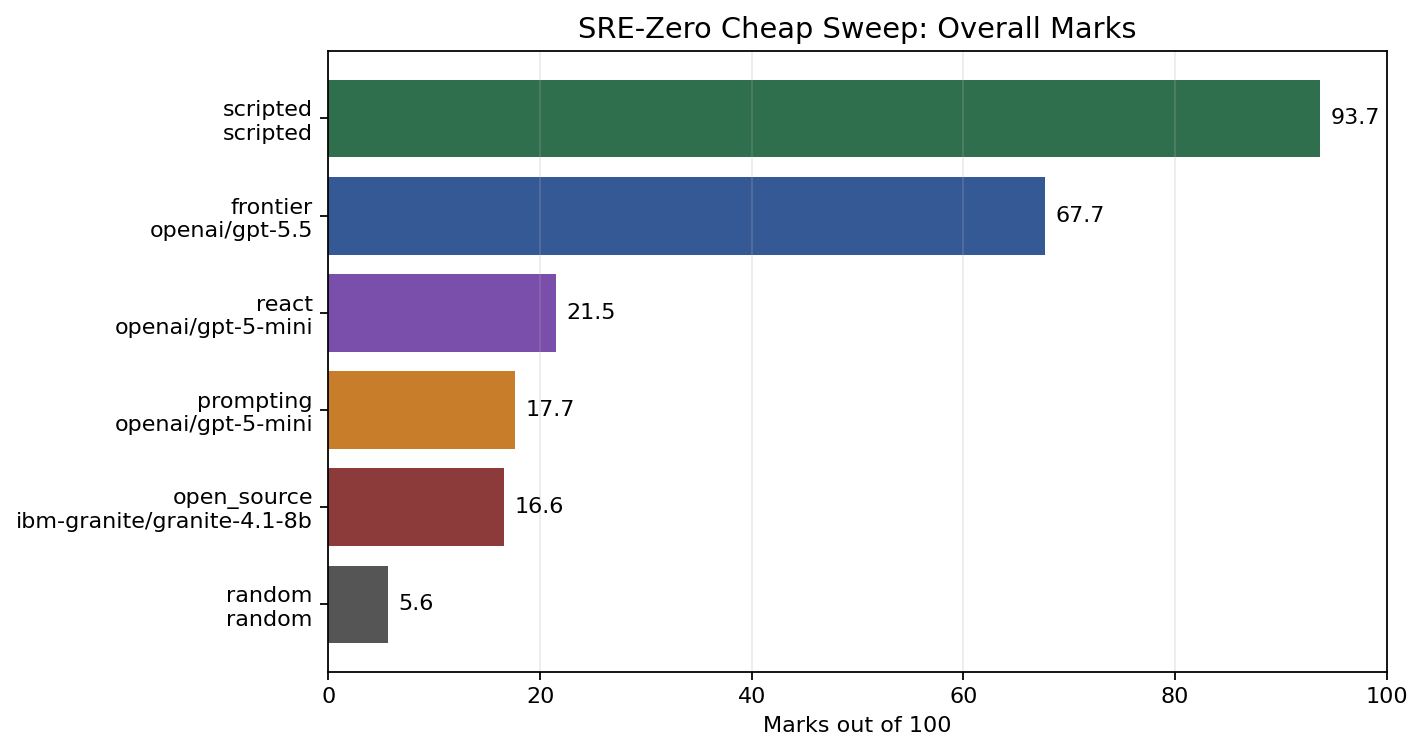
Preliminary baseline results
These numbers are from a small, low-budget sweep over the earlier 15-task suite. Deterministic baselines used 5 episodes per task. LLM baselines used 1 episode per task with seed 0.
| Baseline | Model | Marks | Success | Reward | Evidence | Invalid |
|---|---|---|---|---|---|---|
| Scripted expert | deterministic/scripted | 93.7 | 1.00 | 0.946 | 1.00 | 0.00 |
| Frontier | openai/gpt-5.5 | 67.7 | 0.73 | 0.603 | 0.83 | 0.01 |
| ReAct | openai/gpt-5-mini | 21.5 | 0.00 | 0.040 | 0.81 | 0.15 |
| Prompting | openai/gpt-5-mini | 17.7 | 0.00 | 0.000 | 0.63 | 0.00 |
| Open-source | ibm-granite/granite-4.1-8b | 16.6 | 0.00 | 0.010 | 0.57 | 0.00 |
| Random | deterministic/random | 5.6 | 0.00 | 0.001 | 0.08 | 0.21 |
The scripted expert gives the environment a high upper-bound sanity check. The random agent gives a low floor. The LLM baselines sit between them, and their failure modes are more informative than a single success-rate number.
Why this matters
Many agent evaluations collapse a whole workflow into a final answer. SRE-Zero is designed to expose the intermediate behavior:
- whether the agent inspected relevant evidence
- whether it followed distractors
- whether it applied the right fix
- whether it resolved too early
- whether invalid or repeated actions consumed the budget
This matters for tool-using agents because operational reliability is not only about producing a plausible final sentence. It is about acting in the environment with enough discipline to gather evidence before changing state.
Limitations
The v1 draft is deliberately cautious. These results should not be read as final model rankings.
Important limitations:
- one seed
- one episode per LLM task
- a small model set
- the earlier 15-task suite
- simple simulated services
- no human SRE comparison yet
- no statistical confidence intervals yet
The purpose of this draft is to validate the benchmark design and identify whether the environment produces useful differences between agent strategies.
Next steps
The next stage is to expand the environment beyond the initial suite, run more seeds, evaluate more models, and report confidence intervals. The environment has already started moving toward a larger v0.5 benchmark with additional services, more tasks, noisy metrics, distractor logs, and richer failure metrics.
The current claim is modest: SRE-Zero appears useful as an environment-grounded testbed for separating evidence gathering, remediation quality, final resolution, and action discipline in tool-using agents.
Full artifact downloads
JSON browser
Baseline run JSON records
Baseline agents without API calls:
- Check agent trajectory
- Check summary
- Random failure on misleading web task
- Scripted success on misleading web task
- Baseline no-API summary
Full baseline blog run:
- Random baseline, 5 episodes
- Scripted baseline, 5 episodes
- Prompting, openai/gpt-5-mini
- ReAct, openai/gpt-5-mini
- ReAct, anthropic/claude-sonnet-4.6
- Open-source, google/gemma-4-26b-a4b-it-free
- Open-source, meta-llama/llama-3.3-70b-instruct-free
- Open-source, mistralai/mistral-small-3.2-24b-instruct
- Open-source, nvidia/nemotron-3-super-120b-a12b-free
- Open-source, openai/gpt-oss-20b-free
- Open-source, qwen/qwen3-next-80b-a3b-instruct-free
Earlier cheap sweep:
- Cheap sweep summary
- Random baseline, 5 episodes
- Scripted baseline, 5 episodes
- Prompting, openai/gpt-5-mini
- ReAct, openai/gpt-5-mini
- Open-source, ibm-granite/granite-4.1-8b
- Frontier, openai/gpt-5.5
Expanded deterministic smoke:
Plots and tables
Cheap sweep plots:
- Overall marks plot
- Success vs evidence plot
- Task success heatmap
- Score components plot
- Errors and invalid actions plot
- Results table
Smoke and plotting outputs:
- Expanded smoke metrics table
- Expanded smoke overall marks SVG
- Expanded smoke success vs evidence SVG
- Final push smoke metrics table
- Final push smoke overall marks SVG
- Final push smoke success vs evidence SVG
- Plot-from-eval smoke metrics table
- Plot-from-eval smoke overall marks SVG
- Plot-from-eval smoke success vs evidence SVG
- Plot-script smoke metrics table
- Plot-script smoke overall marks SVG
- Plot-script smoke success vs evidence SVG