Qwen on SRE-Zero Easy: Agent Control Matters
A managed-run report comparing plain prompting, ReAct, and guided open-source-agent control for Qwen on the SRE-Zero easy split.
Qwen on SRE-Zero Easy: Agent Control Matters
This post reports a small managed run from SRE-Zero, using qwen/qwen3.6-35b-a3b on the easy task split.
The goal was not to publish a broad model leaderboard. The goal was narrower: hold the model fixed and compare three agent-control styles under the same deterministic incident-response environment.
The run compares:
- a random baseline
- a scripted expert baseline
- plain open-source Qwen prompting
- ReAct-style Qwen
- guided Qwen, which adds lightweight action validation and sequencing constraints
The run was created and executed through the SRE-Zero managed-run TUI. The raw JSON outputs, summaries, command files, and logs are included with this post under artifacts/, commands/, and logs/.
Important caveat: this is an easy-split, single-seed, one-episode-per-task LLM run. It is useful for validating the benchmark and comparing agent-control behavior, not for final model ranking.
Run setup
The managed run was:
run id: blog-qwen-easy-agent-styles-2026-06-13
difficulty: easy
seed: 0
LLM episodes per task: 1
deterministic episodes per task: 5
target steps: 8
model: qwen/qwen3.6-35b-a3b
The LLM request settings were intentionally conservative because the provider had previously produced transient null-content responses and rate-limit behavior:
timeout seconds: 30
max tokens: 1536
max retries: 5
minimum request interval: 15 seconds
rate limit: 5 requests per 60 seconds
cooldown: 60 seconds after 3 consecutive rejected requests
reasoning excluded: true
Qwen no-think suffix: true
All five targets completed. No target ended with an agent-level runtime error.
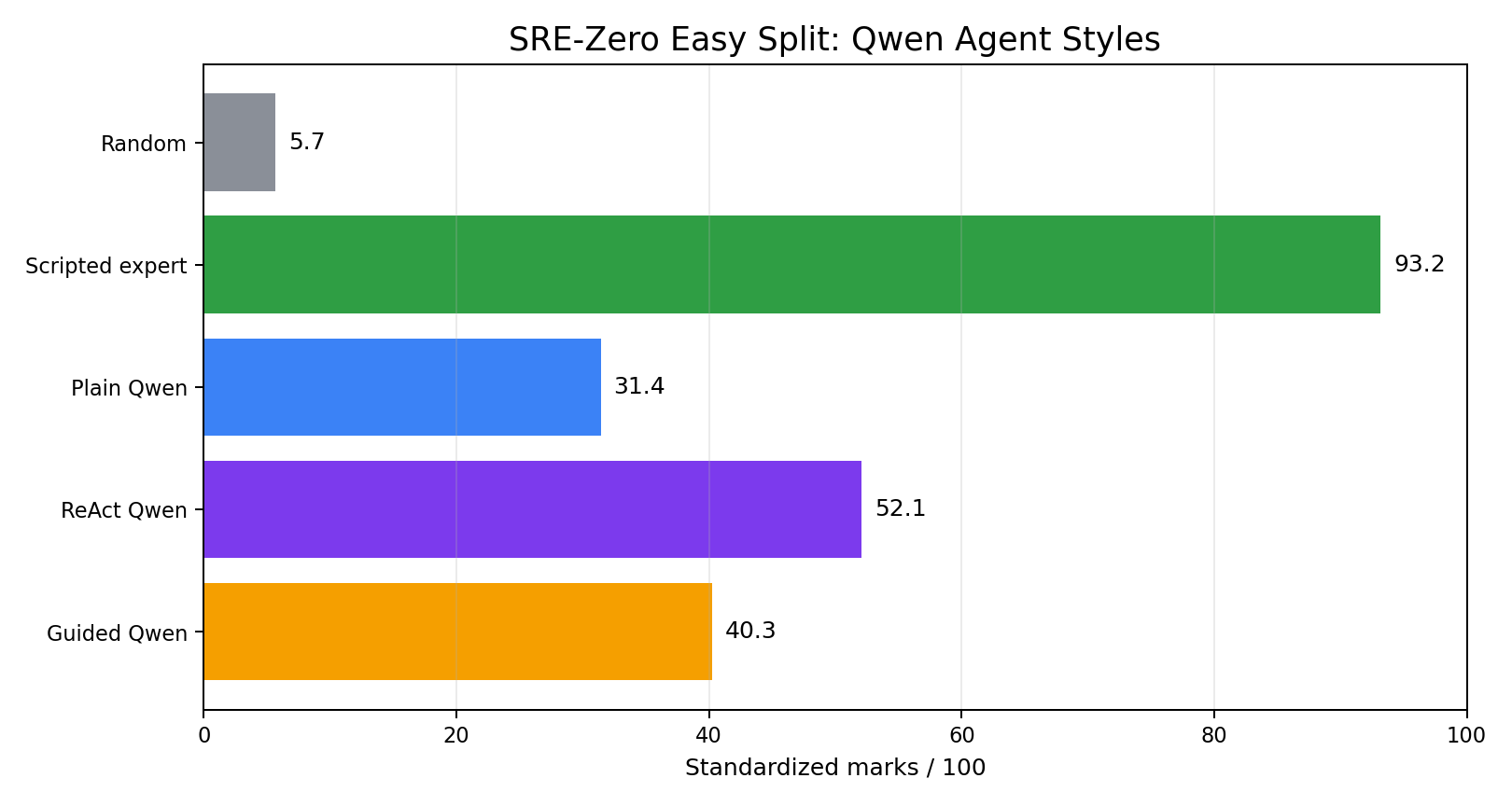
Result table
| Baseline | Model | Marks | Success | Reward | Evidence | Root cause | Fix ID | Correct fix | Premature | Wrong fix | Errors |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random | deterministic/random | 5.7 | 0.0% | 0.005 | 4.8% | 1.8% | 1.8% | 7.3% | 60.0% | 87.5% | 0 |
| Scripted expert | deterministic/scripted | 93.2 | 100.0% | 0.941 | 100.0% | 100.0% | 100.0% | 100.0% | 0.0% | 0.0% | 0 |
| Plain Qwen | qwen/qwen3.6-35b-a3b | 31.4 | 18.2% | 0.217 | 66.7% | 54.5% | 45.5% | 63.6% | 54.5% | 38.1% | 0 |
| ReAct Qwen | qwen/qwen3.6-35b-a3b | 52.1 | 45.5% | 0.511 | 74.2% | 90.9% | 54.5% | 81.8% | 45.5% | 40.0% | 0 |
| Guided Qwen | qwen/qwen3.6-35b-a3b | 40.3 | 27.3% | 0.380 | 69.7% | 63.6% | 27.3% | 63.6% | 45.5% | 58.8% | 0 |
The scripted expert remains the sanity-check upper bound and the random baseline remains the floor. That is useful because it confirms this run is measuring the agent policies rather than a broken task suite.
Among the Qwen variants, the ReAct-style baseline performed best on this split: 52.1 marks and 45.5% success. Plain prompting scored 31.4 marks with 18.2% success. The guided baseline landed between them on marks, but it is interesting for a different reason: it identified root causes often, gathered evidence, and avoided invalid actions, yet still failed frequently at final resolution.
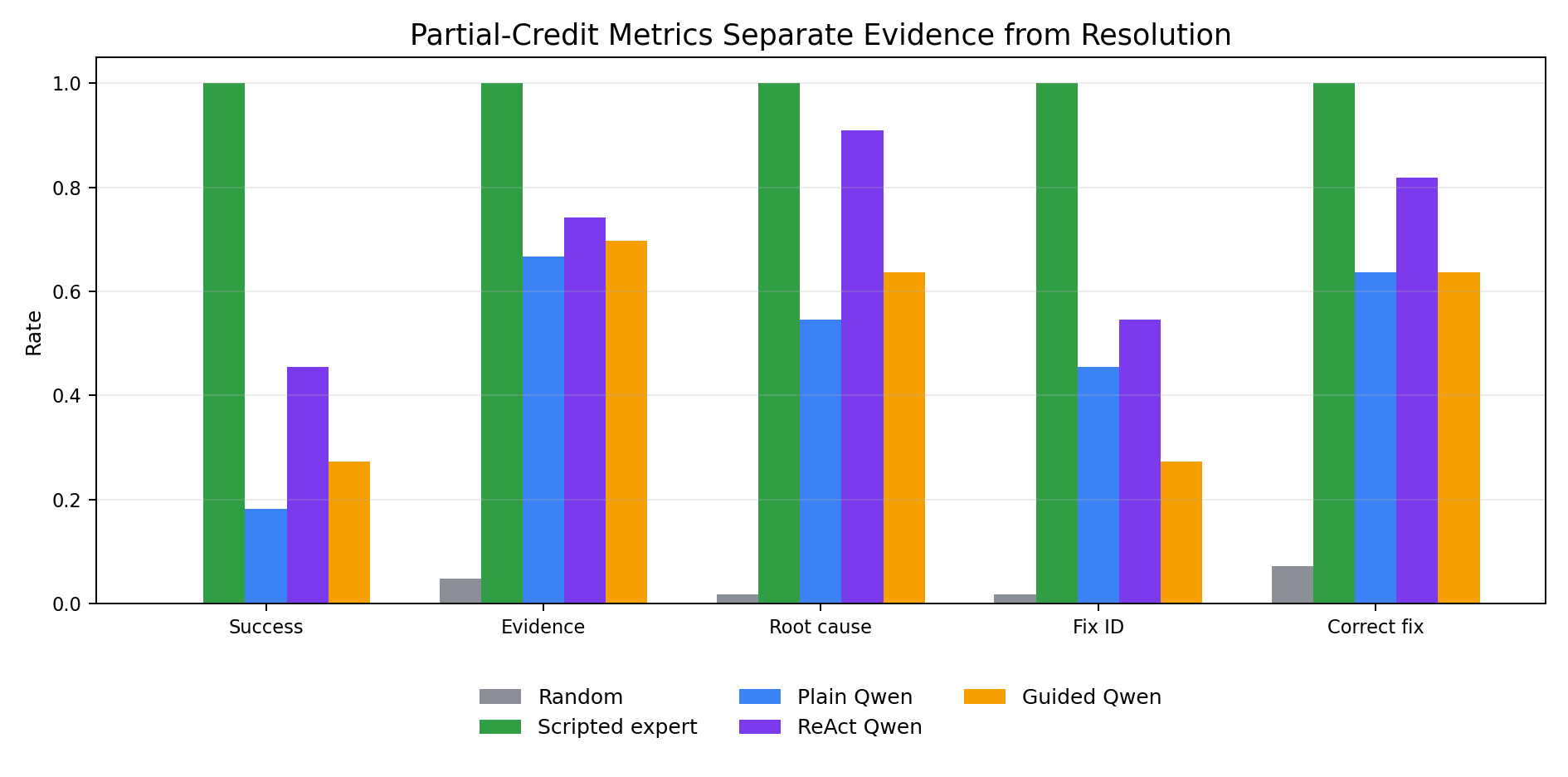
What the partial metrics show
The main benchmark signal is that evidence gathering, diagnosis, remediation, and final resolution are separable.
ReAct Qwen reached:
- 74.2% evidence coverage
- 90.9% root-cause identification
- 81.8% correct remediation rate
- 45.5% final success
That gap matters. The model often found useful information and touched the right fix path, but did not always convert that into a correct terminal incident resolution.
The guided baseline shows a related pattern. It gathered evidence and identified root causes at a reasonable rate, but had a high premature-resolution rate. This suggests the policy wrapper helped keep actions valid and relevant, but did not fully solve the harder part of knowing when the incident was actually resolved.
Failure modes
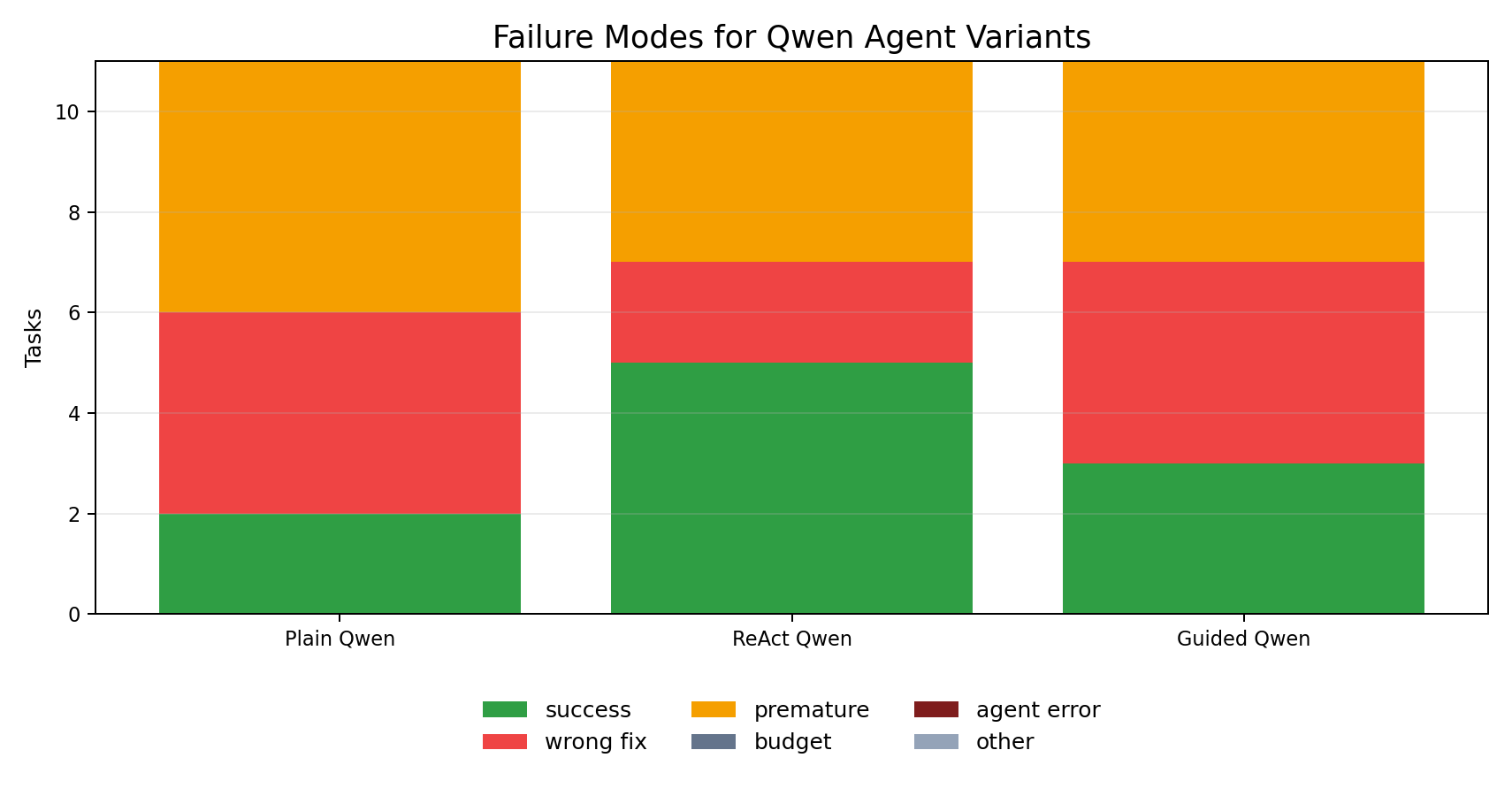
The failures were not dominated by invalid action formatting. Invalid action rate was zero across all Qwen variants in this run.
The more important failures were:
- wrong remediation
- premature or incorrect final resolution
- incomplete conversion from gathered evidence to the exact expected fix
That is a better failure mode for a benchmark than provider errors. It means the environment is exposing agent behavior, not just API instability.
Task-level view
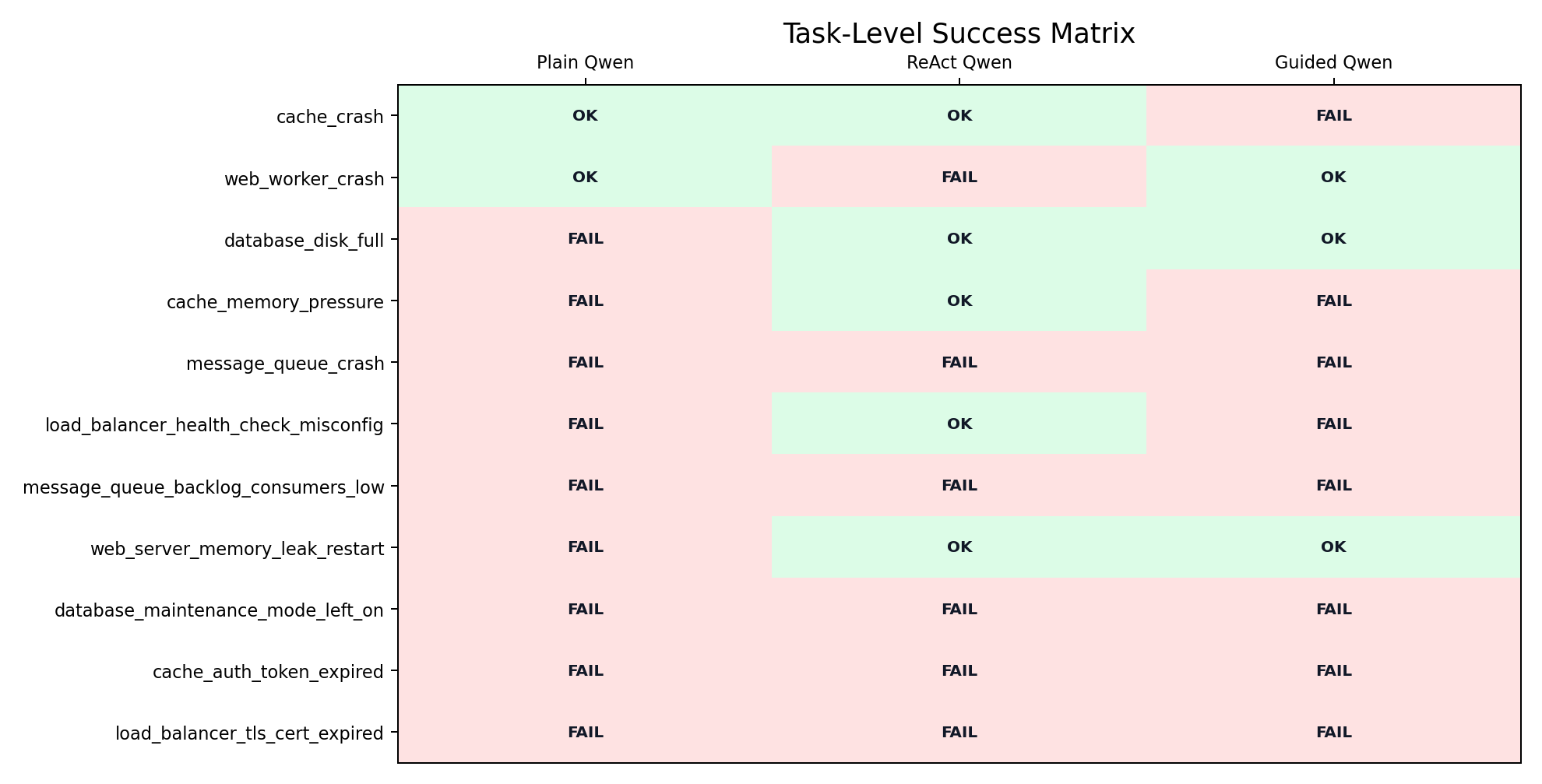
| Task | Plain Qwen | ReAct Qwen | Guided Qwen |
|---|---|---|---|
cache_crash | success (0.875) | success (0.883) | premature_or_incorrect_resolution (0.433) |
web_worker_crash | success (0.633) | premature_or_incorrect_resolution (0.183) | success (0.871) |
database_disk_full | premature_or_incorrect_resolution (0.000) | success (0.850) | success (0.938) |
cache_memory_pressure | premature_or_incorrect_resolution (0.150) | success (0.613) | premature_or_incorrect_resolution (0.000) |
message_queue_crash | premature_or_incorrect_resolution (0.250) | premature_or_incorrect_resolution (0.350) | premature_or_incorrect_resolution (0.183) |
load_balancer_health_check_misconfig | step_budget_exhausted (0.000) | success (0.683) | step_budget_exhausted (0.000) |
message_queue_backlog_consumers_low | premature_or_incorrect_resolution (0.000) | step_budget_exhausted (0.050) | step_budget_exhausted (0.000) |
web_server_memory_leak_restart | premature_or_incorrect_resolution (0.283) | success (0.708) | success (0.883) |
database_maintenance_mode_left_on | step_budget_exhausted (0.133) | premature_or_incorrect_resolution (0.433) | premature_or_incorrect_resolution (0.433) |
cache_auth_token_expired | step_budget_exhausted (0.000) | premature_or_incorrect_resolution (0.433) | step_budget_exhausted (0.000) |
load_balancer_tls_cert_expired | premature_or_incorrect_resolution (0.067) | premature_or_incorrect_resolution (0.433) | premature_or_incorrect_resolution (0.433) |
This task table is the part I find most useful. It shows that the same model succeeds or fails differently depending on the control loop around it.
The plain agent often jumped to a final answer too early. ReAct improved diagnosis and task success. The guided baseline reduced some execution noise, but also surfaced a different failure: being conservative about action structure is not the same thing as being correct about final resolution.
Provider health
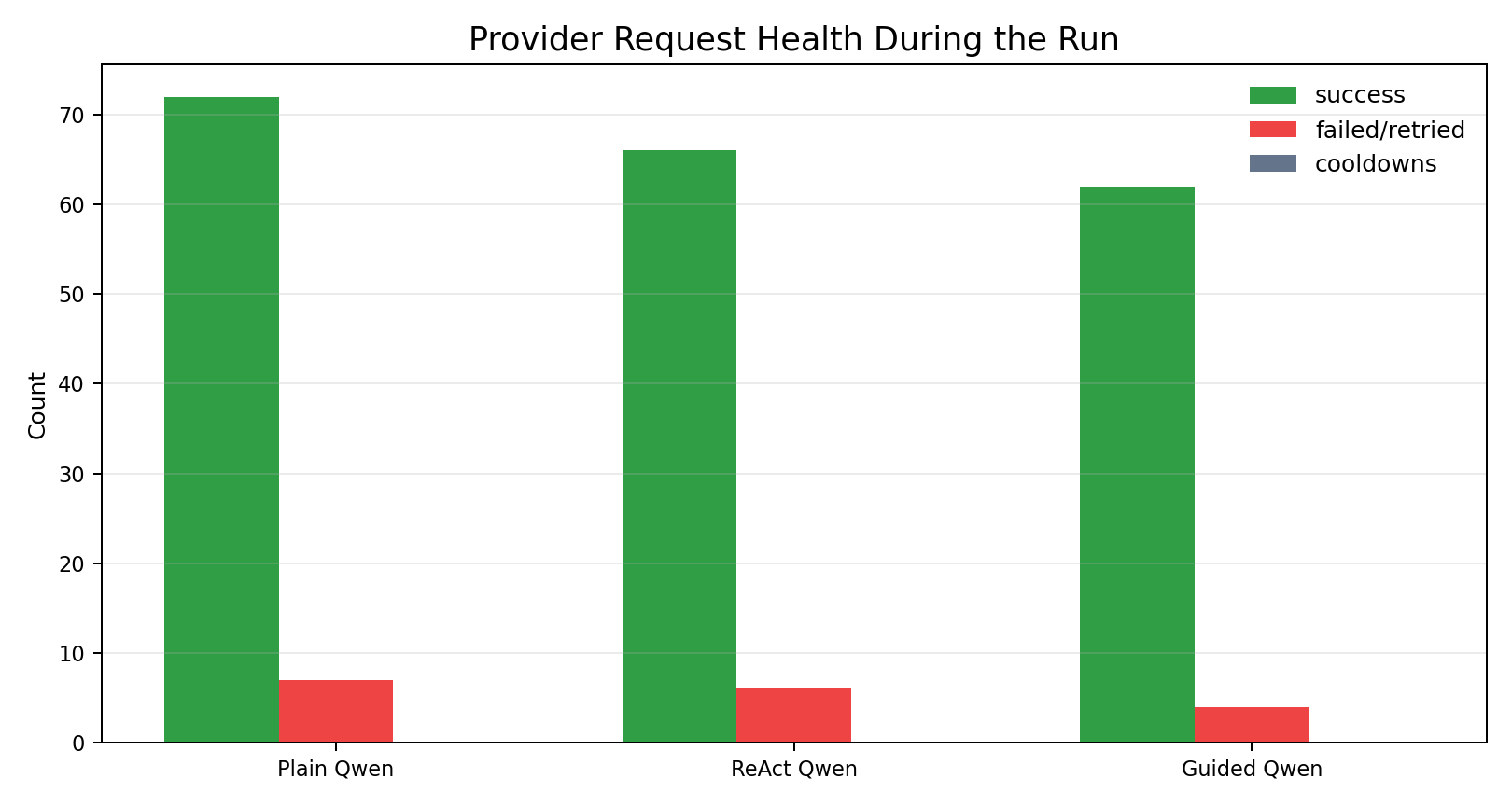
| Baseline | Requests | Successes | Retried failures | Cooldowns |
|---|---|---|---|---|
| Plain Qwen | 79 | 72 | 7 | 0 |
| ReAct Qwen | 72 | 66 | 6 | 0 |
| Guided Qwen | 66 | 62 | 4 | 0 |
There were retryable provider failures, but they did not invalidate this run. The managed runner retried them, no cooldown threshold was reached, and all target outputs completed.
That is a major improvement over earlier runs where model results were too entangled with provider instability.
Attached artifacts
The blog folder includes the source artifacts needed to inspect the run:
JSON records and summaries:
- Open the JSON browser
- Combined summary
- Marks table JSON
- Marks table CSV
- Task outcomes JSON
- Failure modes JSON
- Provider health JSON
- Run config
- Queue state
- Manager state
Command files:
- Random baseline command
- Scripted baseline command
- Plain Qwen command
- ReAct Qwen command
- Guided Qwen command
Logs:
Raw plots:
Takeaway
This run supports the current SRE-Zero thesis: reliable incident-response agents need more than the ability to inspect evidence. They need to decide when enough evidence has been gathered, apply the minimal correct remediation, and then submit a precise resolution under a step budget.
On this easy split, Qwen with ReAct-style control performed meaningfully better than plain prompting. But even the best Qwen variant still left a large gap to the scripted expert, especially on converting partial diagnosis into final resolution.
That gap is exactly the kind of behavior SRE-Zero is meant to make visible.