Mistral Small on SRE-Zero Easy: Evidence Without Enough Closure
A managed-run report comparing plain prompting, ReAct, and guided open-source-agent control for Mistral Small on the SRE-Zero easy split.
Mistral Small on SRE-Zero Easy: Evidence Without Enough Closure
This post reports a small managed run from SRE-Zero, using mistralai/mistral-small-3.2-24b-instruct on the easy task split.
The goal is not to publish a broad model leaderboard. The goal is narrower: hold one model fixed and compare three agent-control styles under the same deterministic incident-response environment.
The run compares:
- a random baseline
- a scripted expert baseline
- plain open-source-agent prompting
- ReAct-style open-source-agent control
- guided open-source-agent control, which adds lightweight action validation and sequencing constraints
The run was created and executed through the SRE-Zero managed-run TUI. The raw JSON outputs, summaries, command files, and logs are included with this post under artifacts/, commands/, and logs/.
Important caveat: this is an easy-split, single-seed, one-episode-per-task LLM run. It is useful for validating the benchmark and comparing agent-control behavior, not for final model ranking.
Run setup
The managed run was:
run id: blog-mistral-small-easy-agent-styles-2026-06-14
difficulty: easy
seed: 0
LLM episodes per task: 1
deterministic episodes per task: 5
target steps: 8.0
model: mistralai/mistral-small-3.2-24b-instruct
The LLM request settings were conservative because the provider has shown transient failures and rate-limit behavior during longer benchmark sweeps:
timeout seconds: 30.0
max tokens: 1536
max retries: 5
minimum request interval: 15.0 seconds
rate limit: 5 requests per 60.0 seconds
cooldown: 60.0 seconds after 3 consecutive rejected requests
reasoning excluded: true
All five targets completed. No target ended with an agent-level runtime error.
Result table
| Baseline | Model | Marks | Success | Reward | Evidence | Root cause | Fix ID | Correct fix | Premature | Wrong fix | Errors |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random | deterministic/random | 5.7 | 0.0% | 0.005 | 4.8% | 1.8% | 1.8% | 7.3% | 60.0% | 87.5% | 0 |
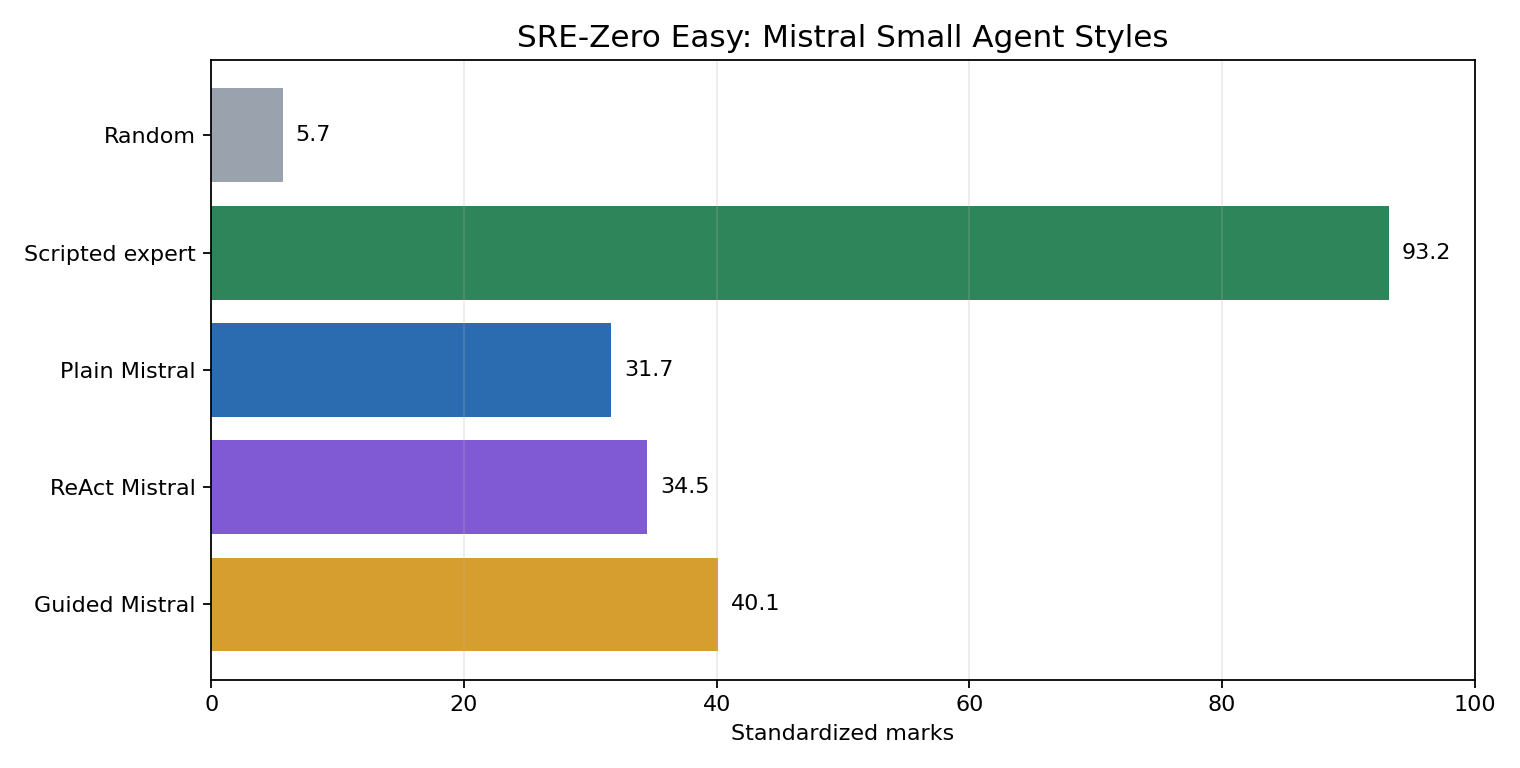
| Scripted expert | deterministic/scripted | 93.2 | 100.0% | 0.941 | 100.0% | 100.0% | 100.0% | 100.0% | 0.0% | 0.0% | 0 |
| Plain Mistral | mistralai/mistral-small-3.2-24b-instruct | 31.7 | 18.2% | 0.206 | 71.2% | 36.4% | 27.3% | 54.5% | 18.2% | 27.8% | 0 |
| ReAct Mistral | mistralai/mistral-small-3.2-24b-instruct | 34.5 | 18.2% | 0.227 | 83.3% | 45.5% | 45.5% | 45.5% | 36.4% | 68.8% | 0 |
| Guided Mistral | mistralai/mistral-small-3.2-24b-instruct | 40.1 | 27.3% | 0.307 | 80.3% | 36.4% | 36.4% | 63.6% | 18.2% | 63.2% | 0 |
The scripted expert remains the sanity-check upper bound and the random baseline remains the floor. That confirms this run is measuring agent behavior on a working task suite rather than a broken evaluation harness.
Among the Mistral Small variants, Guided Mistral had the highest standardized score: 40.1 marks with 27.3% success. Plain prompting scored 31.7 marks with 18.2% success. ReAct scored 34.5 marks, and the guided variant scored 40.1 marks.
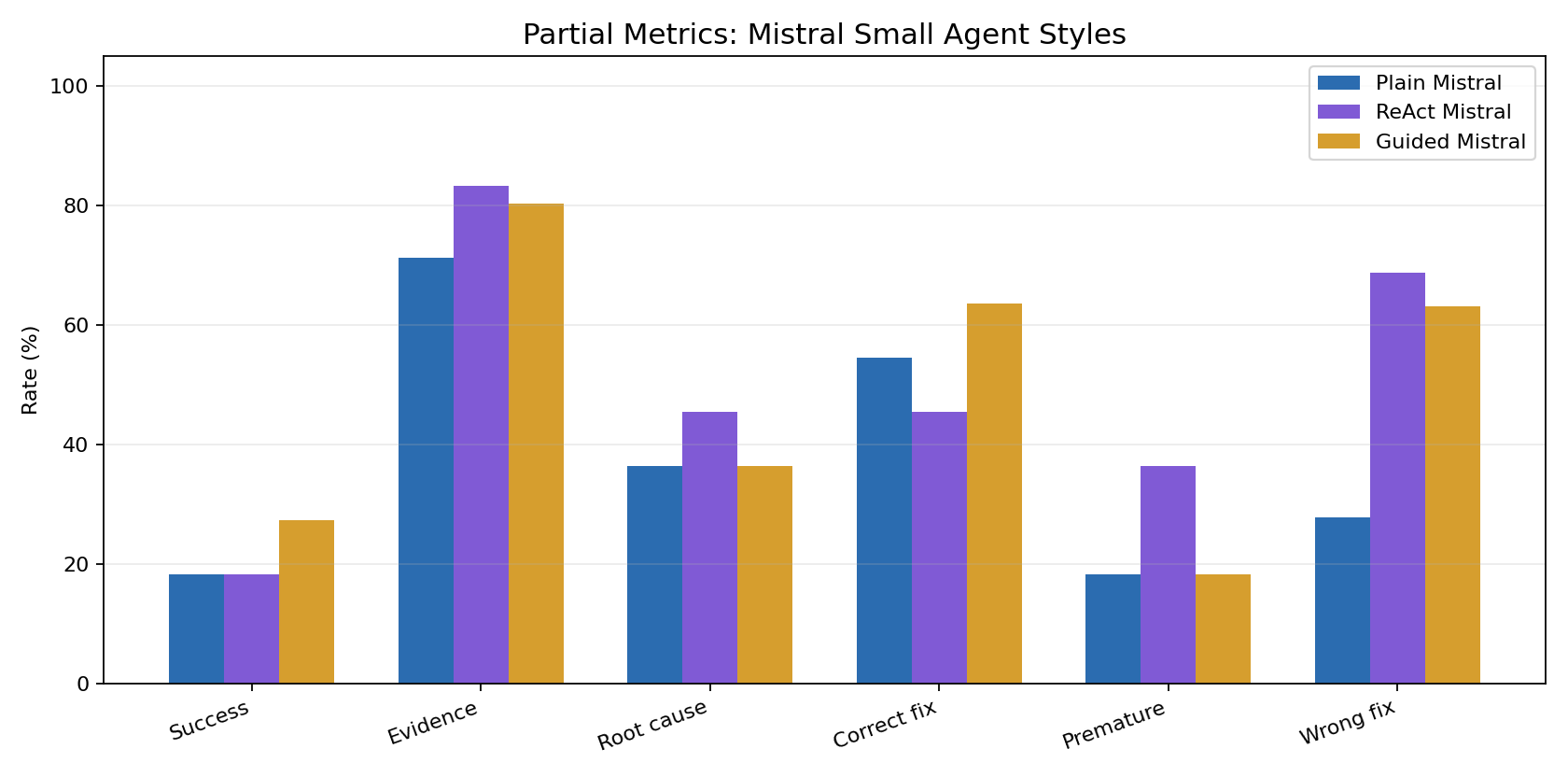
What the partial metrics show
The main benchmark signal is still that evidence gathering, diagnosis, remediation, and final resolution are separable.
The best Mistral Small variant reached:
- 80.3% evidence coverage
- 36.4% root-cause identification
- 63.6% correct-remediation rate
- 27.3% final success
That gap matters. The model often inspected useful state and sometimes touched the right fix path, but did not reliably convert that into a correct terminal incident resolution.
For this run, the interesting behavior is not invalid tool formatting. Invalid-action rates were low across the LLM variants. The harder failure is deciding when the incident is actually resolved and submitting the exact expected root cause and fix.
Failure modes
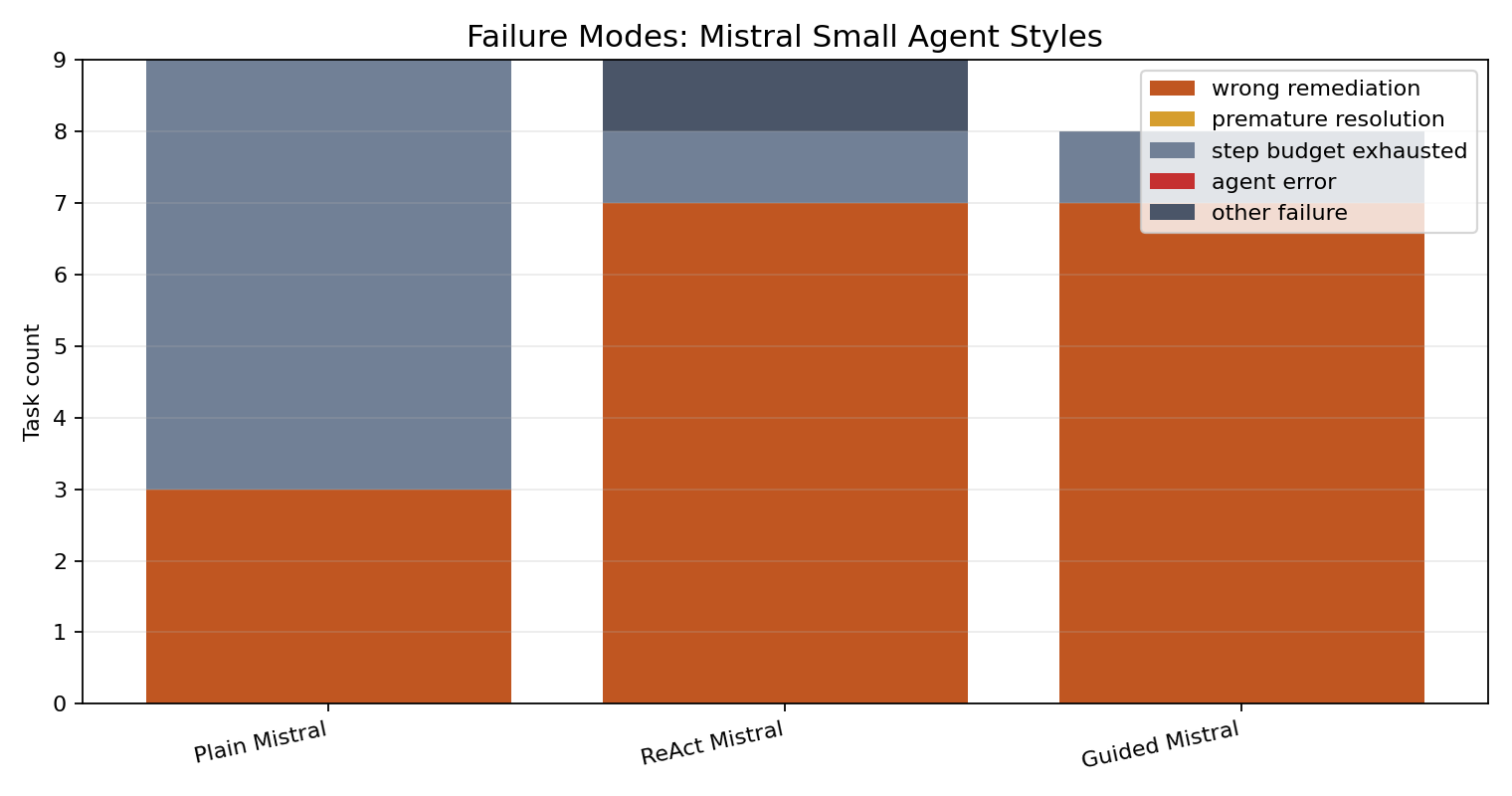
The most useful failures were benchmark-level failures rather than harness crashes: wrong remediation, premature resolution, and step-budget exhaustion.
This is the kind of failure profile SRE-Zero is meant to expose. A model can gather evidence and still fail the incident because it stops too early, applies the wrong fix, or never submits the correct final resolution.
Task-level view
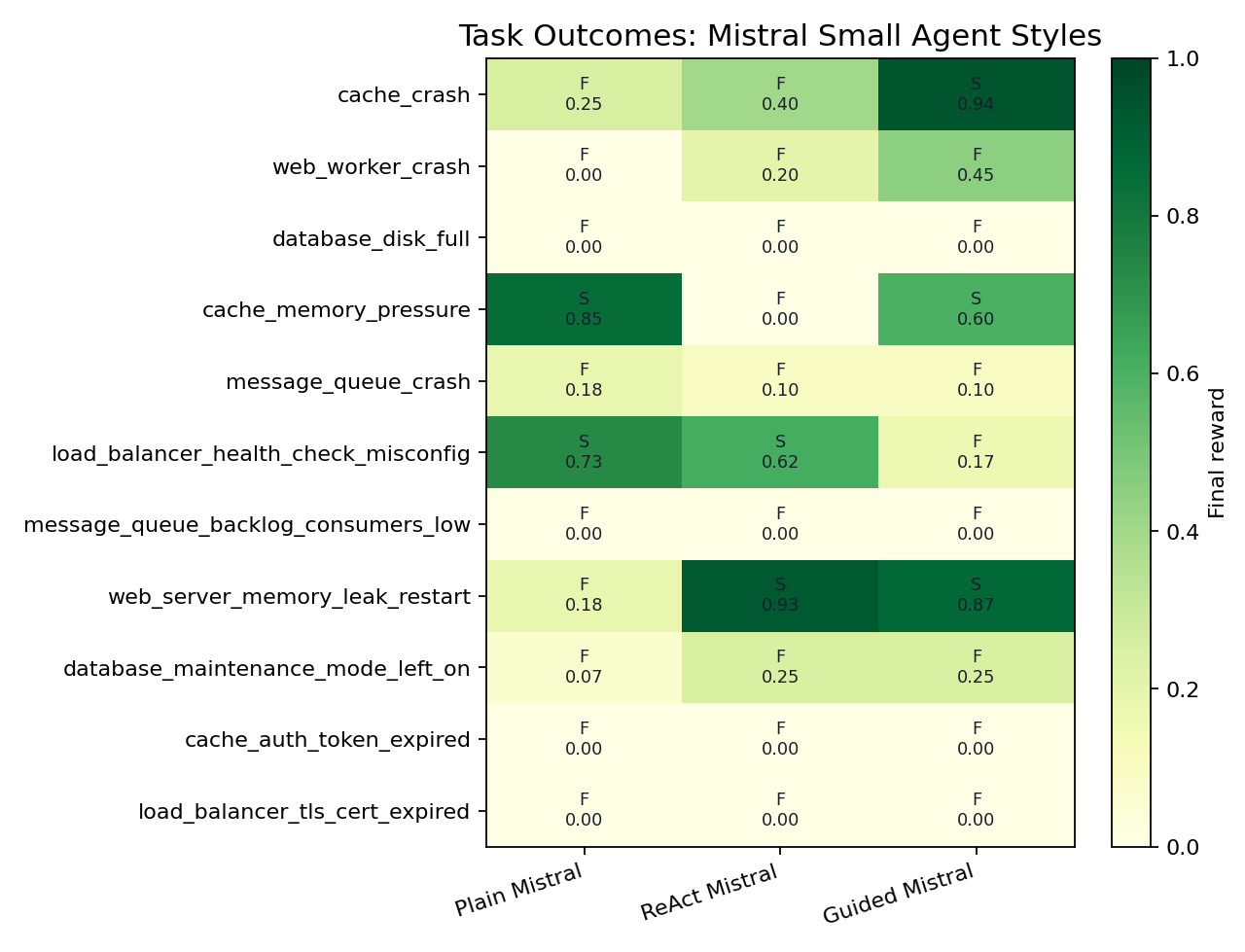
| Task | Plain Mistral | ReAct Mistral | Guided Mistral |
|---|---|---|---|
cache_crash | step_budget_exhausted (0.250) | escalated (0.400) | success (0.938) |
web_worker_crash | step_budget_exhausted (0.000) | step_budget_exhausted (0.200) | step_budget_exhausted (0.450) |
database_disk_full | premature_or_incorrect_resolution (0.000) | step_budget_exhausted (0.000) | escalated (0.000) |
cache_memory_pressure | success (0.850) | premature_or_incorrect_resolution (0.000) | success (0.600) |
message_queue_crash | step_budget_exhausted (0.183) | premature_or_incorrect_resolution (0.100) | premature_or_incorrect_resolution (0.100) |
load_balancer_health_check_misconfig | success (0.733) | success (0.617) | step_budget_exhausted (0.167) |
message_queue_backlog_consumers_low | step_budget_exhausted (0.000) | escalated (0.000) | escalated (0.000) |
web_server_memory_leak_restart | step_budget_exhausted (0.183) | success (0.925) | success (0.871) |
database_maintenance_mode_left_on | step_budget_exhausted (0.067) | premature_or_incorrect_resolution (0.250) | premature_or_incorrect_resolution (0.250) |
cache_auth_token_expired | step_budget_exhausted (0.000) | premature_or_incorrect_resolution (0.000) | escalated (0.000) |
load_balancer_tls_cert_expired | premature_or_incorrect_resolution (0.000) | step_budget_exhausted (0.000) | escalated (0.000) |
The task table is useful because it shows where control style matters. The same underlying model can succeed, fail by budget, or fail by final resolution depending on the loop around it.
Provider health
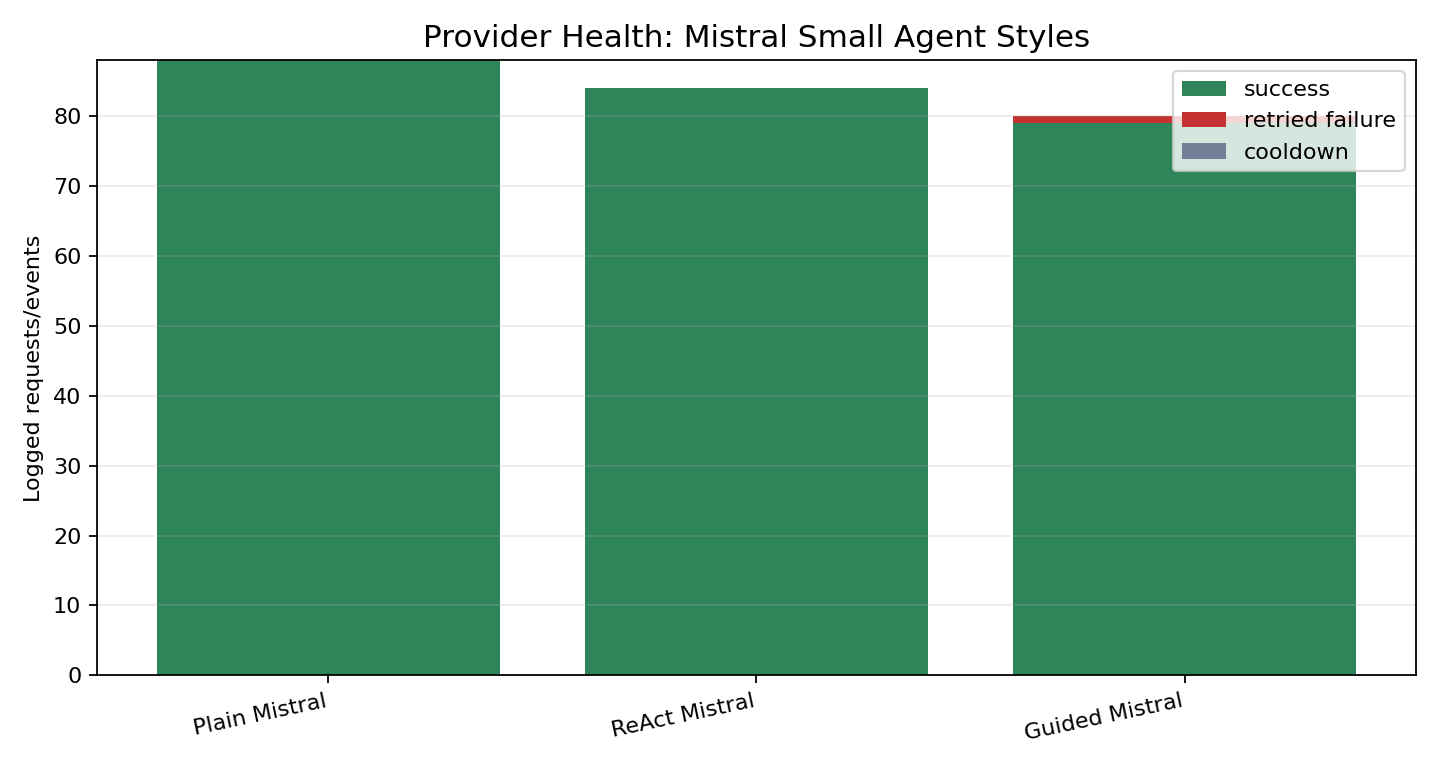
| Baseline | Requests | Successes | Retried failures | Cooldowns |
|---|---|---|---|---|
| Plain Mistral | 88 | 88 | 0 | 0 |
| ReAct Mistral | 84 | 84 | 0 | 0 |
| Guided Mistral | 80 | 79 | 1 | 0 |
There were 1 retryable provider failures across the LLM targets and 0 cooldown events. The managed runner retained the completed artifacts and all targets reached a final output, so this run is publishable as a diagnostic rather than a provider-failure report.
Attached artifacts
The blog folder includes the source artifacts needed to inspect the run.
- Open the blog 8 JSON browser
- Open the blog 8 log explorer
- combined summary
- marks table JSON
- marks table CSV
- task outcomes JSON
- failure modes JSON
- provider health JSON
- run config
- manager state
- queue state
Raw run outputs:
- random baseline, 5 episodes
- scripted expert, 5 episodes
- plain Mistral Small
- ReAct Mistral Small
- guided Mistral Small
Target summaries:
- random summary
- scripted summary
- plain Mistral Small summary
- ReAct Mistral Small summary
- guided Mistral Small summary
Command files:
- random command
- scripted command
- plain Mistral Small command
- ReAct Mistral Small command
- guided Mistral Small command
Raw plots:
- marks by agent plot
- core metrics plot
- failure modes plot
- task success matrix plot
- provider health plot
Takeaway
This run supports the current SRE-Zero thesis: reliable incident-response agents need more than the ability to inspect evidence. They need to decide when enough evidence has been gathered, apply the minimal correct remediation, and then submit a precise resolution under a step budget.
On this easy split, Mistral Small shows useful partial progress, but the gap to the scripted expert remains large. That gap is the point of the benchmark: it makes the difference between tool use, evidence gathering, remediation, and final incident closure visible.