First SRE-Zero Baseline Results: Evidence Is Easier Than Resolution
A first small benchmark sweep across random, scripted, prompting, ReAct, open-source, and frontier baselines in SRE-Zero.
First SRE-Zero Baseline Results: Evidence Is Easier Than Resolution
I ran the first small benchmark sweep for SRE-Zero, the simulated incident-response environment I am building to study reliable tool-using agents.
This is still early research code. The goal of this run is not to rank models or make broad claims about capability. The goal is narrower: to check whether SRE-Zero can produce useful, inspectable differences between agent strategies.
The early signal is encouraging. The scripted expert solves the benchmark, the random baseline behaves like a weak floor, and the LLM baselines show a useful failure pattern: smaller prompting-style agents often gather relevant evidence, but they do not reliably convert that evidence into a minimal fix and final incident resolution.
Run setup
This was a cheap local sweep intended for a first blog post, not a final paper result.
- Task suite: 15 deterministic incident-response tasks
- Services:
web_server,database,cache - Deterministic baselines: 5 episodes per task
- LLM baselines: 1 episode per task
- Seed:
0 - LLM timeout: 90 seconds
- Output directory:
notes/runs/blog_cheap_sweep
Baselines in this run:
- random baseline
- scripted expert baseline
- prompting baseline with
openai/gpt-5-mini - ReAct-style baseline with
openai/gpt-5-mini - open-source LLM baseline with
ibm-granite/granite-4.1-8b - frontier model baseline with
openai/gpt-5.5
I refer to openai/gpt-5.5 as the frontier baseline in this local setup, not as a general benchmark of frontier-model capability.
The LLM runs use an OpenAI-compatible provider configured locally through .env.
Because the LLM baselines use only one episode per task, these numbers should be treated as directional signals rather than statistically stable estimates.
Results
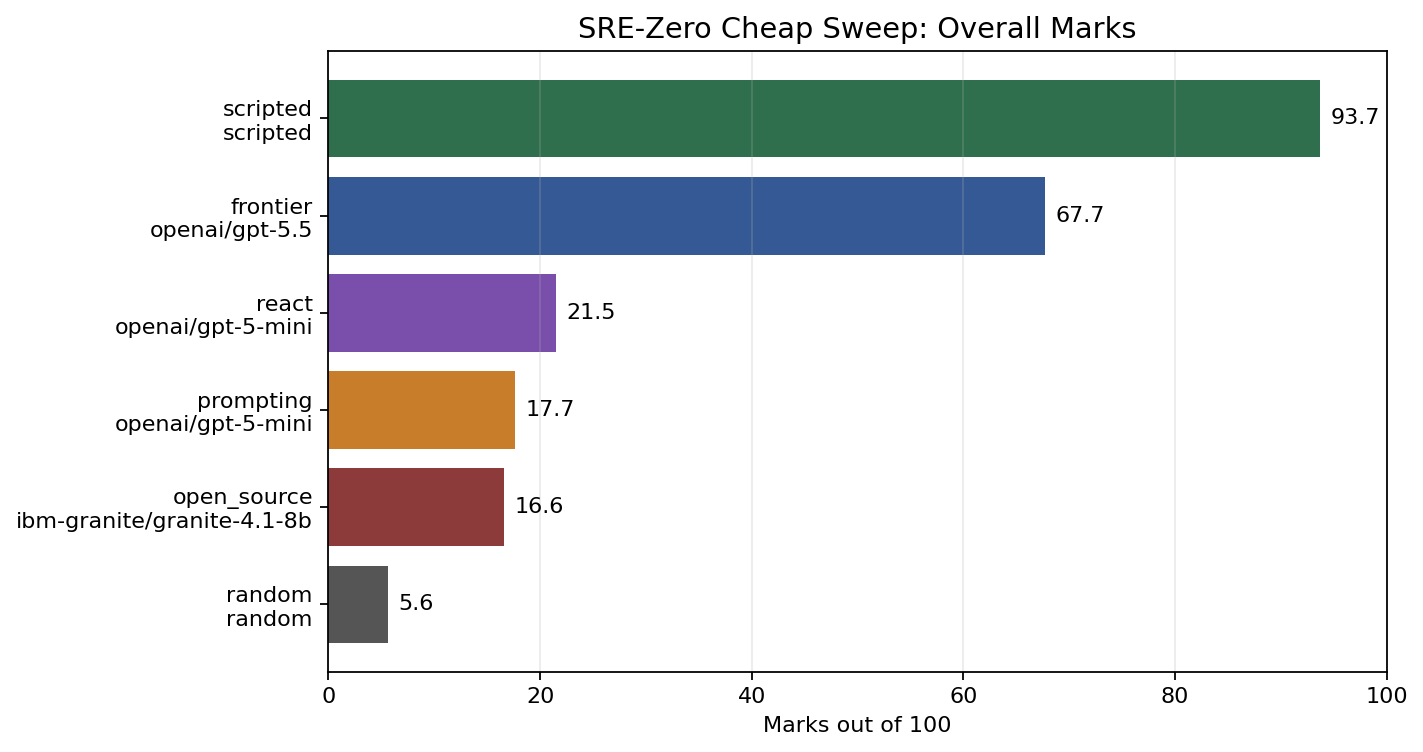
"Marks" is a composite score from 0-100 combining success, reward, evidence coverage, invalid-action rate, efficiency, and error penalties.
| Baseline | Model | Marks | Success | Reward | Evidence | Invalid | Steps | Errors |
|---|---|---|---|---|---|---|---|---|
| scripted | deterministic/scripted | 93.7 | 1.00 | 0.946 | 1.00 | 0.00 | 4.47 | 0 |
| frontier | openai/gpt-5.5 | 67.7 | 0.73 | 0.603 | 0.83 | 0.01 | 6.40 | 1 |
| react | openai/gpt-5-mini | 21.5 | 0.00 | 0.040 | 0.81 | 0.15 | 4.40 | 13 |
| prompting | openai/gpt-5-mini | 17.7 | 0.00 | 0.000 | 0.63 | 0.00 | 3.73 | 12 |
| open_source | ibm-granite/granite-4.1-8b | 16.6 | 0.00 | 0.010 | 0.57 | 0.00 | 8.20 | 0 |
| random | deterministic/random | 5.6 | 0.00 | 0.001 | 0.08 | 0.21 | 3.69 | 0 |
The scripted expert acts as an approximate upper bound for this version of the benchmark. It solves every task, gathers all required evidence, and finishes in about 4.47 steps on average.
The random baseline gives a useful floor. It gets almost no reward, gathers little evidence, and has a high invalid action rate.
The frontier baseline is the first non-scripted agent that resolves a meaningful fraction of the benchmark. In this run it solved 11 of 15 tasks, with 0.83 evidence coverage and low invalid-action rate.
The smaller prompting, ReAct, and open-source baselines show a different pattern. They often inspect relevant logs or metrics, but they usually fail to take the next step: apply the correct remediation and submit a final resolution.
The important result is not that the frontier baseline scores higher. The important result is that SRE-Zero exposes where agents fail inside the trajectory: observation, diagnosis, remediation, or final resolution.
Evidence is not the same as resolution
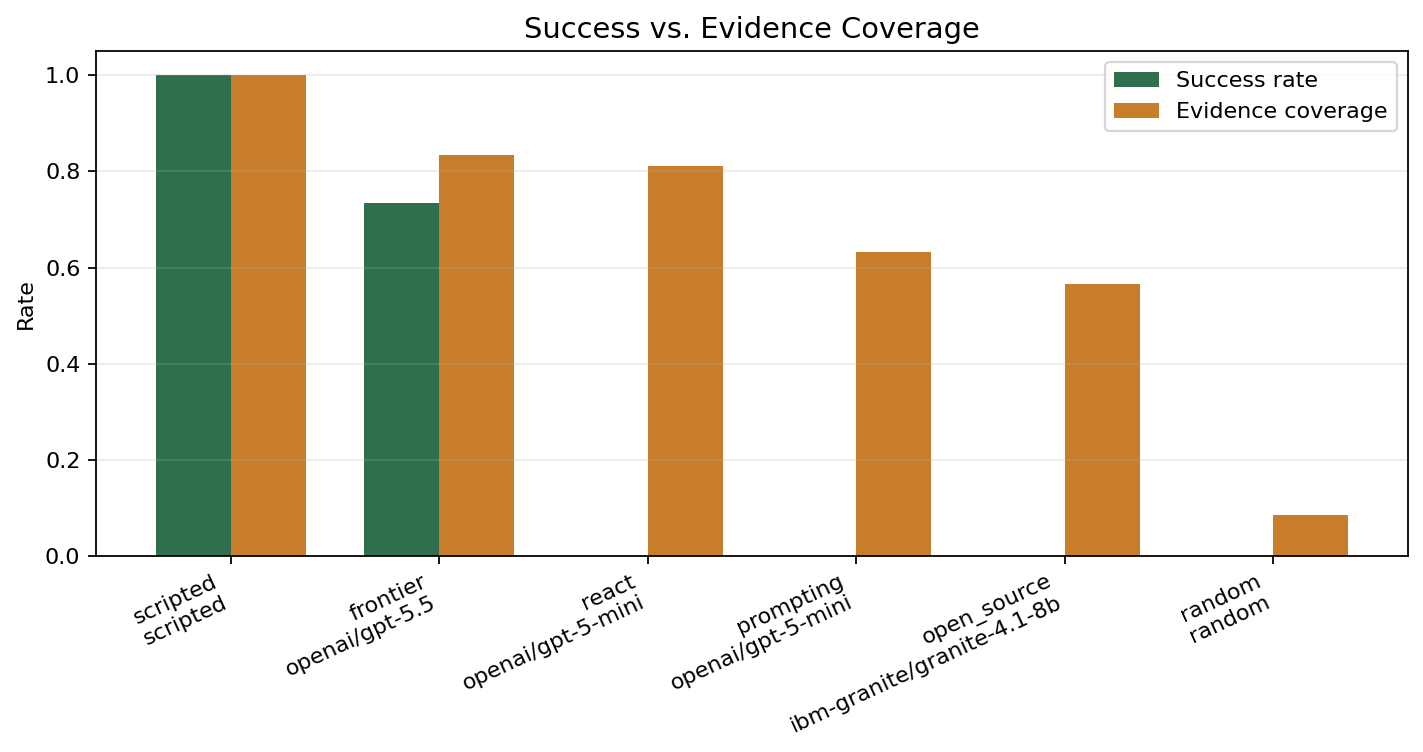
The most interesting early signal is the gap between evidence coverage and success.
The ReAct-style openai/gpt-5-mini baseline reached 0.81 evidence coverage but had 0.00 success rate. The prompting baseline reached 0.63 evidence coverage and also had 0.00 success rate.
That means the agents were not simply failing to use tools. They were often using the right inspection tools. The failure was later in the workflow:
- gather evidence
- identify the root cause
- apply the correct minimal fix
- submit a correct resolution
Current prompting baselines are getting part of step 1, then stalling, repeating inspections, or failing before remediation.
This is exactly the kind of behavior SRE-Zero is meant to expose. A final-answer benchmark would likely miss this distinction. An environment benchmark can separate "looked in the right place" from "actually resolved the incident."
Task-level behavior
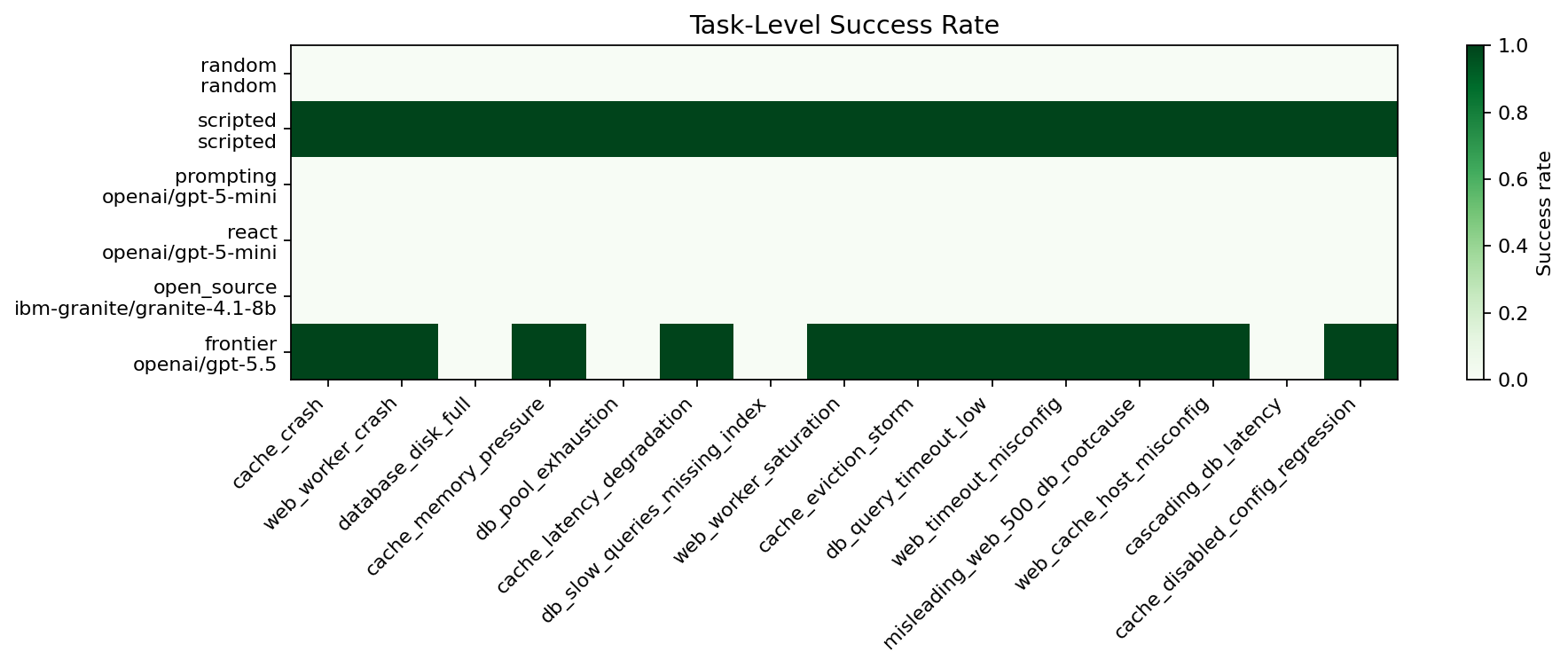
The frontier model solved most cache and web-server tasks, including:
cache_crashweb_worker_crashcache_memory_pressurecache_latency_degradationweb_worker_saturationcache_eviction_stormdb_query_timeout_lowweb_timeout_misconfigmisleading_web_500_db_rootcauseweb_cache_host_misconfigcache_disabled_config_regression
The failures are also informative. The frontier run failed on:
database_disk_fulldb_pool_exhaustiondb_slow_queries_missing_indexcascading_db_latency
In several of those failures, evidence coverage was still high. For example, database_disk_full, db_pool_exhaustion, and db_slow_queries_missing_index all reached 1.00 evidence coverage, but the final task success was still 0.00.
That suggests the hard part is not only observation. It is converting observations into a correct root-cause statement, a safe remediation, and the final resolution call.
Score components
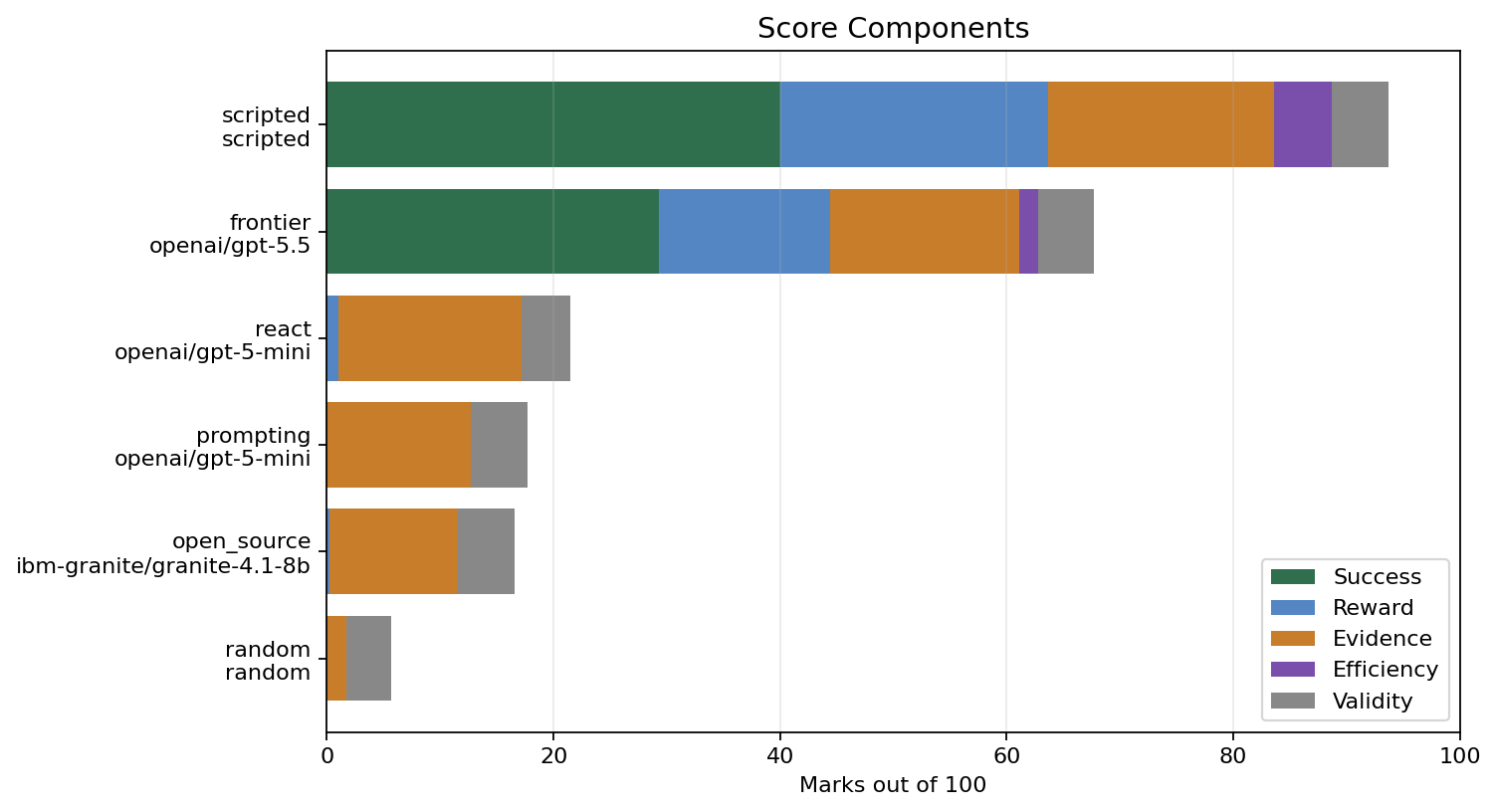
The score is intentionally not just success rate.
SRE-Zero also gives partial credit for evidence gathering, remediation behavior, final resolution, efficiency, and valid action use. This matters because a failed incident can still reveal whether an agent was close, whether it used tools sensibly, and where it broke down.
For example:
- random gets almost no evidence credit and many invalid actions
- prompting gets some evidence credit but no success
- ReAct gets more evidence credit but also more invalid actions and provider errors
- frontier gets meaningful success credit but still loses marks on unresolved tasks
- scripted expert is high but not exactly 100 because the score includes efficiency and shaping details
This makes the benchmark more useful for failure analysis than a pass/fail-only setup.
Reliability issues showed up too
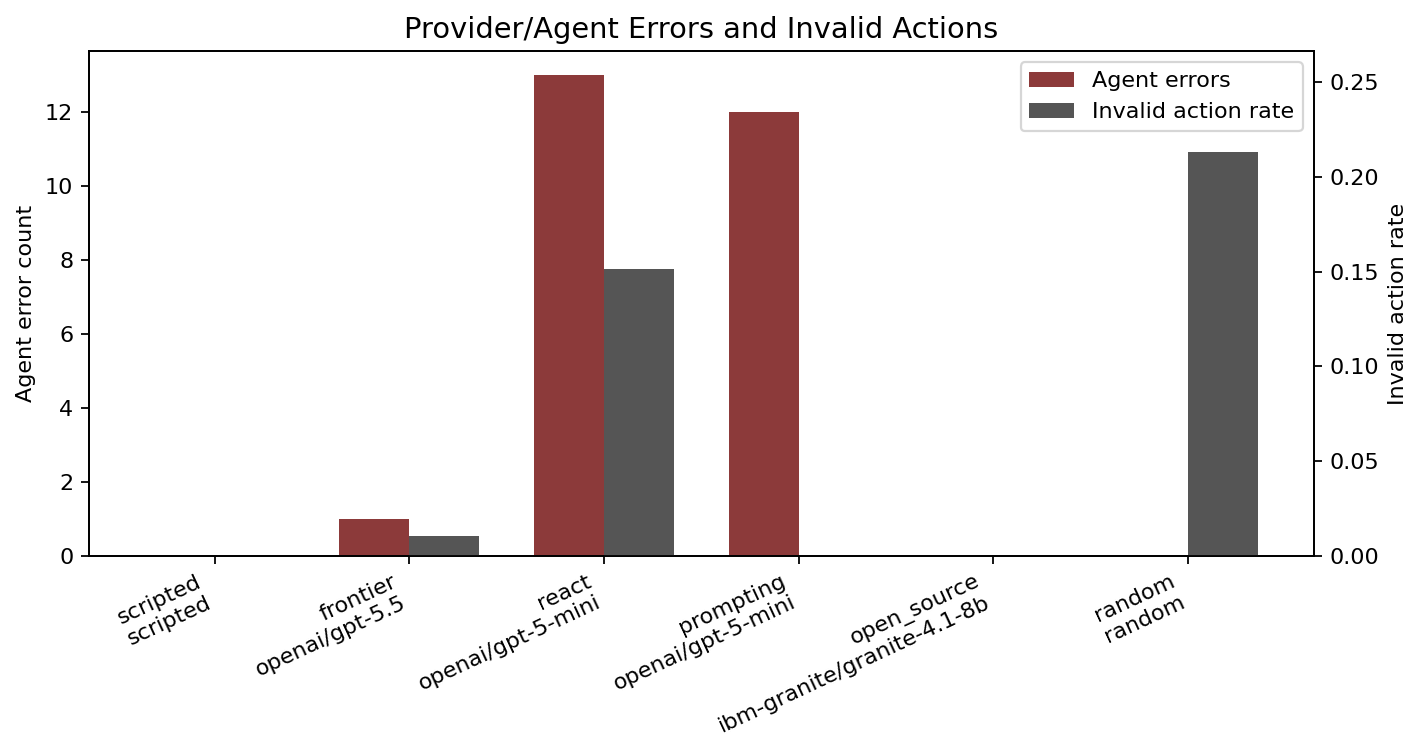
There were provider or response-format errors during the LLM runs. In this sweep, several failures were recorded as:
RuntimeError: Unexpected message content type: NoneType
This is a useful reminder that agent reliability is not only about reasoning. A tool-using benchmark also needs to measure whether the model and provider path consistently produce usable actions.
The environment handled these failures without crashing the entire sweep. The errors are stored in the JSON records and counted in the marks table.
What this suggests
My current takeaway is cautious but useful:
SRE-Zero is already producing separable failure modes.
The first results distinguish:
- random invalid tool use
- scripted upper-bound behavior
- evidence gathering without remediation
- repeated inspection loops
- provider response failures
- partial success on easier incidents
- failures on incidents requiring precise database remediation
That is a good sign for the benchmark design. It means the environment is not only producing a final score. It is producing trajectories that can be inspected and turned into research questions.
Limitations
This is not a full evaluation yet.
- The LLM baselines used only one episode per task.
- The model set is small.
- The run used one seed.
- The provider path can return null message content, which affected several LLM baselines.
- The scripted expert uses task-specific knowledge and should be treated as an upper-bound baseline, not a realistic agent.
- The tasks are still simulated and deterministic.
So the right interpretation is not "model X is best." The right interpretation is:
This early environment can measure evidence gathering, action validity, remediation behavior, and resolution success separately.
That is the core thing I wanted from this phase.
Next steps
The next benchmark pass should:
- run more episodes per task
- repeat across seeds
- compare more models per baseline type
- improve LLM response parsing and null-content handling
- add token and cost accounting
- write a more formal experiment table for the paper draft
- add plots for per-difficulty performance
SRE-Zero is still early, but this run is the first useful signal: tool use alone is not enough. Evidence gathering is only one part of reliable incident response. The harder problem is turning evidence into the right minimal action under a budget.